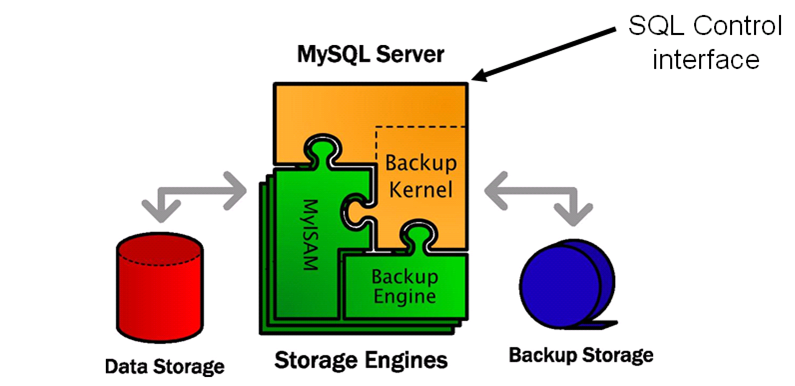
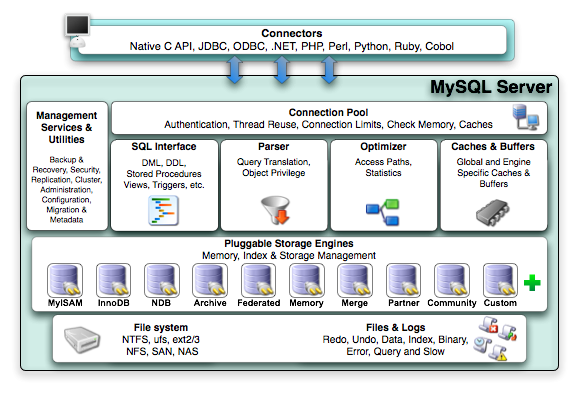
출처 : https://mariadb.com/kb/ko/mariadb-mysql/#mariadb와-mysql-proxy의-비호환성
MariaDB는 MySQL을 즉시 교체할 수 있는 바이너리이다
모든 실용적인 목적에서 MariaDB는 동일한 MySQL 버전을 즉시 교체할 수 있다. (예를 들어 MySQL 5.1은 MariaDB 5.1, MariaDB 5.2, MariaDB 5.3과 호환되며, MySQL 5.5은 MariaDB 5.5와 호환된다.) 이는 다음과 같은 것을 의미한다.
- 데이터와 테이블 정의 파일 (.frm) 파일들이 호환된다
- 모든 클라이언트 API, 프로토콜 및 구조가 동일하다
- 모든 파일이름, 바이너리, 경로, 포트, 소켓이 모두 동일해야 한다
- 모든 MySQL 커넥터(PHP, Perl, Python, Java, .NET, MyODBC, Ruby, MySQL C connector 등)는 아무런 변화없이 MySQL에서 잘 작동한다
- 몇몇 PHP5에서의 설치 이슈가 존재한다. (오래된 PHP 클라이언트가 라이브러리 호환성을 검사하는 데서 발생하는 버그이다)
- 클라이언트 공유 라이브러리는 MySQL 클라이언트 라이브러리와 호환된다.
이는 대부분의 경우에서 MySQL을 언인스톨한 뒤, MariaDB를 설치해도 잘 작동한다는 것을 의미한다. (동일한 메인 버전에서는 데이터 파일을 변환할 필요없다.)
우리는 월간 주기로 MySQL 코드를 병합하여 호환성을 보장하며 오라클이 추가하는 기능 및 버그 수정도 MariaDB에 포함된다.
우리는 업그레이드 스크립트에 많은 작업을 완료하여 MySQL 5.0에서 MySQL 5.1로 업그레이드하는 것보다 MySQL 5.0에서 MariaDB 5.1로 업그레이드하는 것이 더 쉽도록 하였다.
하지만, MariaDB는 MySQL에 없는 새로운 옵션, 확장, 저장 엔진, 버그 수정도 많이 포함하고 있다. 서로 다른 MariaDB 버전별 기능은 MariaDB 릴리즈별 차이 에서 확인할 수 있다.
MariaDB 5.1과 MySQL 5.1의 비호환성
일부 경우 MariaDB는 MySQL보다 더 많은 정보를 보여주기 위하여 비호환성을 허용하고 있다.
다음 목록은 MySQL 5.1 대신 MariaDB 5.1을 사용하는 경우에 알려진 모든 사용자 레벨의 비호환성 목록이다.
- 설치 패키지 이름은 MySQL 대신 MariaDB로 시작한다.
- Timings may be different as MariaDB is in many cases faster than MySQL.
- MariaDB의 mysqld는 my.cnf에서
[mariadb]섹션을 읽는다. - You can't use a binary only storage engine library with MariaDB if it's not compiled for exactly the same MariaDB version. (This is because the server internal structure THD is different between MySQL and MariaDB. This is common also between different MySQL versions). This should not be a problem as most people don't load new storage engines and MariaDB comes with more storage engines than MySQL.
CHECKSUM TABLE은 다른 결과를 출력할 수 있다. MariaDB는 NULL을 무시하지 않지만, MySQL 5.1은 NULL을 무시하기 때문에 이러한 차이가 발생한다. (향후 MySQL은 MariaDB가 계산하는 방식대로 체크섬을 계산해야 할 것이다) 옛날 방식의 체크섬을 얻길 원한다면--old옵션으로 MariaDB를 실행하면 된다. 하지만, MariaDB의 MyISAM과 Aria 저장 에닌은 내부적으로 새로운 체크섬을 이용한다. 따라서--old옵션을 이용하는 경우CHECKSUM명령은 매 레코드마다 체크섬을 계산하기 때문에 속도가 느릴 것이다.- 슬로우 쿼리 로그는 쿼리에 대한 더 많은 정보를 제공하는데, 이는 슬로우 쿼리 로그를 직접 파싱하는 경우 문제가 될 수 있다.
- MariaDB는 내부에서 사용하는 임시 테이블을 기본으로 Aria 저장 엔진을 사용하기 때문에 MySQL보다 메모리를 좀 더 사용한다. MariaDB가 최소한의 메모리만 더 사용하길 원하는 경우
aria_pagecache_buffer_size를1M로 설정하면 된다. (기본 값은128M). - 만약 새로운 명령 옵션, MariaDB의 새로운 기능 혹은 새로운 저장 엔진, 을 사용하는 경우 더 이상 MySQL과 MariaDB 사이를 오갈 수 없다.
MariaDB 5.2와 MySQL 5.1의 비호환성
Incompatibilities between MariaDB 5.2 and MySQL 5.1
MariaDB 5.1과 MySQL 5.1의 비호환성과 동일하며 1가지가 추가된다.
SQL_MODE에 새로운 값이 추가되었다. 새롭게 추가된 값은 IGNORE_BAD_TABLE_OPTIONS이며, 이 값이 설정되지 않은 경우, 현재 사용 중인 저장 엔진에서 지원되지 않는 테이블, 필드, 인덱스의 속성을 사용하는 경우 에러를 발생한다. 이런 변화로 인해 에러 로그에는 다음과 같은 경고 메시지가 발생할 수 있다. "mysql 데이터베이스에 잘못 정의된 테이블이 있음. mysql_update를 이용하려 수정하시오"
모든 실용적인 목적에서 MySQL 5.2는 MariaDB 5.1과 MySQL 5.1을 즉시 대체 가능하다.
MariaDB 5.3, MySQL 5.1, MariaDB 5.2의 비호환성
- 잘못된 변환에 관련된 일부 에러 메시지가 MariaDB에서 좀 더 자세히 제공된다.
- MariaDB에 특화된 오류 번호는 1900번부터 시작하여 MySQL 오류 번호와 충돌되지 않는다.
- MySQL은 일부 문맥에서 datetime과 time에서 마이크로초를 손실했지만, MariaDB는 모든 문맥에서 마이크로초가 잘 작동한다.
- UNIX_TIMESTAMP (상수 날짜 문자열)은 MariaDB에서는 마이크로초 단위까지 표현이 가능히지만 MySQL은 그렇지 못하다. 이는 UNIX_TIMESTAMP()를 파티션 함수로 사용하는 경우 문제가 될 수 있는데, FLOOR(UNIX_TIMESTAMP(..)) 를 이용하거나 날짜 문자열을 숫자형 (예를 들어 20080101000000 형식)으로 바꿔서 해결할 수 있다.
- MariaDB는 date, datetime, timestamp 값에 대해 더 엄격한 검사 수행한다. 예를 들어 UNIX_TIMESTAMP('x') 는 0이 아닌 NULL을 반환한다.
--maria-시작 옵션은 제거되었다. 대신에--aria-prefix를 사용해야 한다. (MySQL 5.2는--maria--와--aria-모두 지원함)SHOW PROCESSLIST는Progress라는 추가적인 컬럼이 존재하며 일부 명령에 대해 진행 상황을 보여준다. 이 기능은mysqld시작 시--old옵션을 이용하여 끌 수 있다.INFORMATION_SCHEMA.PROCESSLIST는 진행 보고를 위해 다음과 같은 3개의 추가적인 컬럼을 출력한다:STAGE,MAX_STAGE, andPROGRESS./*M!혹은<<code>>/*!#<</code>로 시작하는 긴 주석은 주석이 아니라 실제 실행이 된다.max_user_connections=0는 연결 수를 제한 두지 않는 것을 의미하는데, mysqld 시작 시 이 옵션을 사용하는 경우 mysqld가 실행 중인 경우는 이 전역 변수를 수정할 수 없다.<<code>>max_user_connections=s<</code>로 mysqld가 시작된 경우 연결 개수를 위한 구조체를 할당하지 않기 때문이다. mysqld 실행 중에 이 값을 바꾸고 싶다면 0이 아닌 큰 값을 지정하는 것이 좋다.max_user_connections를-1로 설정하여 (전역 변수인GRANT옵션도 동시에) 사용자가 서버에 접속하는 것을 중지시킬 수 있다. 전역 변수max_user_connections는SUPER권한을 가진 사용자에게는 영향을 미치지 않는다.- |IGNORE 지시자는 모든 오류를 무시하지 않는다 (예:FATAL 오류). 무시를 해도 안전한 오류만 무시한다.
MariaDB 5.3과 MySQL 5.3의 비호환성
XtraDB
XtraDB를 제공하는 Percona는 5.5 코드 기반에게 초기 기능의 모든 것을 제공하지 않았따. 따라서 MariaDB 5.5 또한 그 기능을 제공하지 못한다.
5.5에 없는 XtraDB 옵션들
다음의 옵션들은 XtraDB 5.5에서 지원되지 않는다. 만약 당신이 my.cnf에서 아래의 옵션을 사용 중이라면 5.5로 업그레이드 전에 제거해야 한다.
- innodb_adaptive_checkpoint ; Use
innodb_adaptive_flushing_methodinstead. - innodb_auto_lru_dump ;Use
innodb_buffer_pool_restore_at_startupinstead. - innodb_blocking_lru_restore ; Use
innodb_blocking_buffer_pool_restoreinstead. - innodb_enable_unsafe_group_commit
- innodb_expand_import ; Use
innodb_import_table_from_xtrabackupinstead. - innodb_extra_rsegments ; Use
innodb_rollback_segmentinstead. - innodb_extra_undoslots
- innodb_fast_recovery
- innodb_flush_log_at_trx_commit_session
- innodb_overwrite_relay_log_info
- innodb_pass_corrupt_table ; Use
innodb_corrupt_table_actioninstead. - innodb_use_purge_thread
- xtradb_enhancements
기본 값이 변경된 XtraDB의 옵션
XtraDB options that has changed default value
| 옵션 | 기존 값 | 새로운 값 |
|---|---|---|
| innodb_adaptive_checkpoint | TRUE | ?FALSE |
| innodb_change_buffering | inserts | ?all |
| innodb_flush_neighbor_pages | 1 | ?area |
XtraDB 5.5의 새로운 옵션
다음의 옵션들은 XtraDB / InnoDB 5.5에 새롭게 추가된 옵션이다. (Listed here just to have all XtraDB information in the same place)
- innodb_adaptive_flushing_method
- innodb_adaptive_hash_index_partitions
- innodb_blocking_buffer_pool_restore
- innodb_buffer_pool_instances
- innodb_buffer_pool_restore_at_startup
- innodb_change_buffering_debug
- innodb_corrupt_table_action
- innodb_flush_checkpoint_debug
- innodb_force_load_corrupted
- innodb_import_table_from_xtrabackup
- innodb_large_prefix
- innodb_purge_batch_size
- innodb_purge_threads
- innodb_recovery_update_relay_log
- innodb_rollback_segments
- innodb_sys_columns
- innodb_sys_fields
- innodb_sys_foreign
- innodb_sys_foreign_cols
- innodb_sys_tablestats
- innodb_use_global_flush_log_at_trx_commit
- innodb_use_native_aio
5.5로 업그레이를 위한 Percona의 가이드 도 참조하는 것이 좋다.
MariaDB 5.5, MariaDB 5.3과 MySQL 5.5의 비호환성
- 중복 키 오류에서
INSERT IGNORE는 경고 메시지를 출력한다.
MariaDB 10.0과 MySQL 5.6의 비호환성
- MySQL의 모든 바이너리 (
mysqld, myisamchk 등)은 예를 들어--big-tables대신--big-table옵션을 사용하는 경우 경고 메시지를 출력하는 반면, MariaDB 바이너리는 다른 대부분의 유닉스 명령들과 동일한 방식으로 작동하며, 유일한 prefix로 사용될 경우 경고를 출력하지 않는다.
지원되지 않는 설정
my.cnf에서 다음의 옵션을 사용 중인 경우 해당 변수를 제거해야 한다. 이는 MySQL 5.1 및 그 이후 버전에서도 마찬가지다.
skip-bdb
MySQL RPM 교체
만약 MySQL RPM을 제거하고 MariaDB를 설치하고자 하는 경우 MySQL RPM은 /etc/my.cnf를 /etc/my.cnf.rpmsave로 이름을 변경한다.
MariaDB를 설치한 뒤에는 다음과 같이 MySQL RPM 당시의 my.cnf를 복원할 수 있다.
mv -vi /etc/my.cnf.rpmsave /etc/my.cnf
MariaDB와 MySQL-Proxy의 비호환성
MySQL 클라이언트 API는 MySQL-Proxy를 통하여 MariaDB에 연결할 수 있다. 그러나 MariaDB 클라이언트 API는 "진행 보고(progress reporting)"을 MySQL-Proxy가 지원하지 않는다는 정보를 받게 된다. 완벽한 호환성을 위해서는 "진행 보고"를 클라이언트 측이나 서버 측에서 중지시키면 된다.
'MySQL' 카테고리의 다른 글
| [MySQL] show engine innodb status \G; (0) | 2016.06.02 |
|---|---|
| [펌][Mysql] *MySQL 쓰면서 하지 말아야 할 것 17가지* (0) | 2016.06.02 |
| [MySQL] 버전별 기능(Features) 변경 이력 (0) | 2016.06.01 |
| [MySQL] mysqldump 시 lock tables (0) | 2016.05.31 |
| [펌][MySQL] 비교 연산자 (1) | 2016.03.04 |