Logical Session 에 대해서 정리 하였습니다.
한글로 된 자료도 많지가 않아서 초등이하 수준의 영어를 번역기 돌리고 나쁜 머리로 이해하고 쓰느라 부족한 부분이 많습니다. 부디 저의 글이 도움이 되어, 보다 자세하고 정확한 글들이 나오길 기대하는 마음으로 작성하였습니다.
-
server session 또는 logical session 은 클라이언트에서 Causal Consistency 와 다시 쓰기 시도(retryable write)와 같은 기본 프레임 워크를 지원
-
Logical session(식별자)을 생성함으로써, single operation 또는 multiple-operation transaction에서 사용되는 리소스를 추적이 가능
- 이러한 프레임 워크를 이용하여 Transaction 을 구현이 가능
- Logical session 과 Logical session Identifier(식별자) 를 만드는데, 이것을 lsid라고 하고 lsid는 유니크한 값으로 mongodb cluster와 client간 연결
- MongoDB 3.6이후로는 client 조작은 모두 logical session 과 연관되며, lsid가 클러스터 전체에서 명령어의 조작과 관련
- lsid를 이용하여 특정 lsid 를 식별하는게 쉬워지고 전체 프로세스가 단순해 짐
- 컨트롤러 프로세스가 연결된 lsid를 5분마다 수집하고 30분 후에 트리거되는 ttl 인덱스를 이용하여 30분간 재사용 되지 않는 session에 대해서는 리소스 정리가 가능
-
application 은 client session 을 이용하여 server session 을 이용
- server session 은 replica set / sharded cluster 에서만 사용 가능
|
option
|
type
|
description
|
|
lsid
|
Document
|
명령을 실행하는 session 의 고유 ID(GUID-Global Unique ID)를 지정
txnNumber 는 lsid 가 반드시 필요
|
|
txnNumber
|
64 bit integer
|
명령 세션에서 명령을 고유하게 식별하는 양수
lsid 옵션도 함께 필요
|
cf) RDBMS 는?
단일노드에서 읽기 및 쓰기를 서비스하기 때문에 자연스럽게 Casual Consistency 으로 알려진 읽기 및 쓰기 작업에 대한 순차적 순서 보증을 제공
하지만 분산 시스템은 이러한 보증을 제공할 수 있지만 이렇게 하기 위해서 모든 노드에서 관련 이벤트를 조정하고 정렬해야 특정 작업이 완료 될 수 있는 속도를 제한 필요
Casual Consistency 는 모든 데이터 순서 보증이 유지되는 경우를 이해하는 것이 가장 쉽지만, 시스템이 노드 충돌이나 네트워크 파티션과 같은 장애에 직면할 때에도 시스템이 해야 할 많은 일관성과 내구성 트레이드 오프가 존재
-
v3.6
-
인과적 일관성이라고 번역
-
읽기 쓰기 등이 순차적 순서를 보장하는 것을 의미
- 연산이 앞선 연산에 논리적인 의존성을 가지는 경우(동일한 데이터에 접근), 이 두 연산은 causal relationship을 가졌다고 표현
- 이때, 클라이언트 어플리케이션에서는 반드시 한번에 한 쓰레드만이 이 연산들을 시도하도록 보장해야만 함
-
일관성을 보장하기 위한 작업을 의미
-
Write / Read Concern 이 모두 majority 가 casual consistency 를 보장
-
참고로 분산 시스템에 대한 일반적인 데이터 개념 (단순 Mongodb만 해당 하는 것이 아님)
- 주요 memory 일관성 모델 중 하나
- 공유 메모리에 접근하는 프로그래밍에서 일관성 모델은 어떤 access 가 정확한 순서인지를 제한
- 분산 공유 메모리 또는 분산 트랜잭션에서 올바른 데이터 구조를 정의하는데 유용
-
분산시스템이 Scale up/down 만 가능한 DBMS를 모방한 작업 순서를 보장 기능
-
majority 를 이용하여 읽기, 쓰기에 대한 완전한 일관성을 보장하지만, 사용 사례로 다양하게 사용 가능
-
Causal Consistency는 read / write 어떤 연산을 수행과 상관없이 동작하는데 이 때 비용이 발생하기에, 단조적 읽기 보장(monotonic read guarantees)이 필요한 곳에만 사용함으로써 causal consistency에 의한 지연을 최소화할 수 있음
-
반드시 아래 내용 해석 정리 필요
|
read your writes
|
read operations reflect the results of write operations that precede them
(읽기 작업은 앞에 있는 쓰기 작업의 결과를 반영합니다.)
|
|
Monotonic reads
(단조로운 읽기)
|
Read operations do not return results that correspond to an earlier state of the data than a preceding read operation.
읽기 작업은 이전 읽기 작업보다 이전 데이터 상태에 해당하는 결과를 반환하지 않습니다.
|
|
Monotonic write
(단조로운 쓰기)
|
Write operations that must precede other writes are executed before those other writes.
다른 쓰기보다 선행되어야 하는 쓰기 작업은 해당 다른 쓰기보다 먼저 실행됩니다.
|
|
Writes follow reads
읽기 다음 쓰기
|
Write operations that must occur after read operations are executed after those read operations.
쓰기 작업은 읽기 작업 후에 발생해야 합니다,
|
-
Casual Consistency 가 없는 경우
- 전제 사항으로 읽기작업은 secondary에서 진행하기 때문에, Primary 에 쓰기 작업 이후 바로 secondary에서 읽을 때 Write가 성공 되었다고 하지만, 복제 보다 먼저 read를 요청하여 write 작업이 반영 안된 현상 발생
- 단순히 replica set 을 예를 들었지만, Sharded cluster 에서도 동일한 문제가 발생 가능

- Casual Consistency 가 없는 경우 해결방법
- Lamport logical clock 을 기반으로 하이브리드 logical clock 을 구현
- Primary에서 write 되는 이벤트에는 primary 시간이 할당
- primary 시간은 모든 구성원 노드가 해당 시간으로 비교 진행
- 모든 DML(write)에 대해서는 각각의 최신 시간을 할당하고, 해당 시간으로 구성원 노드들이 비교하여 순서를 따져 작업 진행

-
Write Concern / Read Concern 은 Casually consistent 작업 집합 내, 각 작업에 적용할 수 있는 설정
-
Write concern에는 latency와 durabillity (내구성) 중 하나를 선택
-
Read Concern 의 경우 isolation level과 연관이 있음(commit 된 snapshot 에 반영된 데이터를 이용)
-
이러한 작업들은 모두 시스템 장애 시 데이터 보존에 영향(read / write concern)
-
여러 샤드에서 transaction 일 때, transaction 에서 변경 중인 데이터라고 transaction 외부에서 해당 데이터를 무조건 볼수 없는 것이 아닌, read concern이 local인 경우, 특정 샤드 내 커밋된 데이터는 볼 수 있음 (Transaction 내 A, B 샤드에 걸쳐서 write 가 발생 중인데, 이 때 A는 commit 되고, B에서는 commit 되기 전이라면, A의 commit 된 데이터는 read concern 이 local 상황에서 조회가 가능)
-
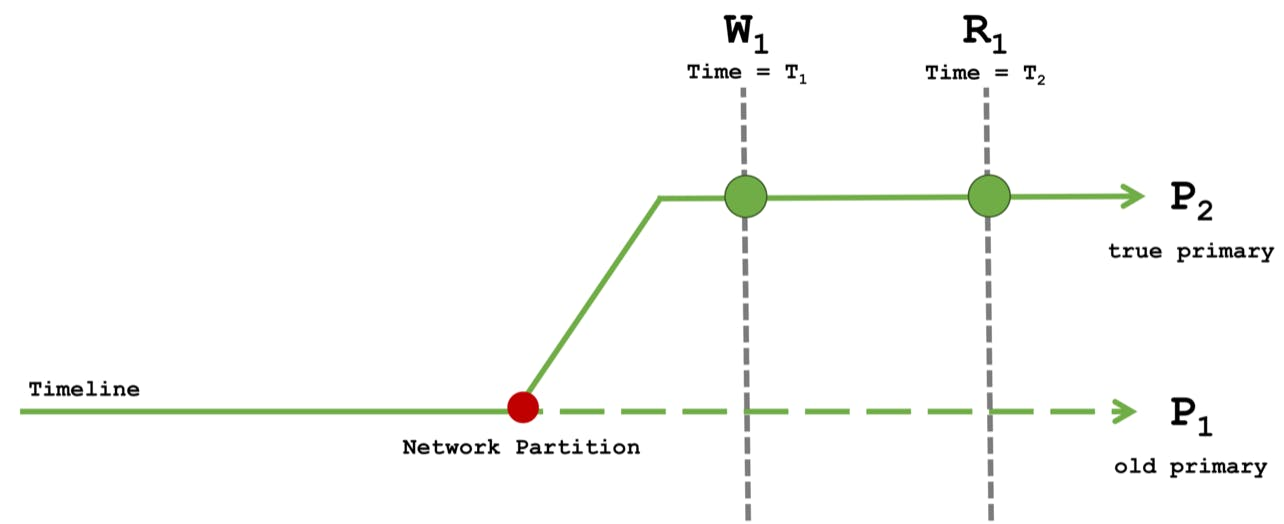
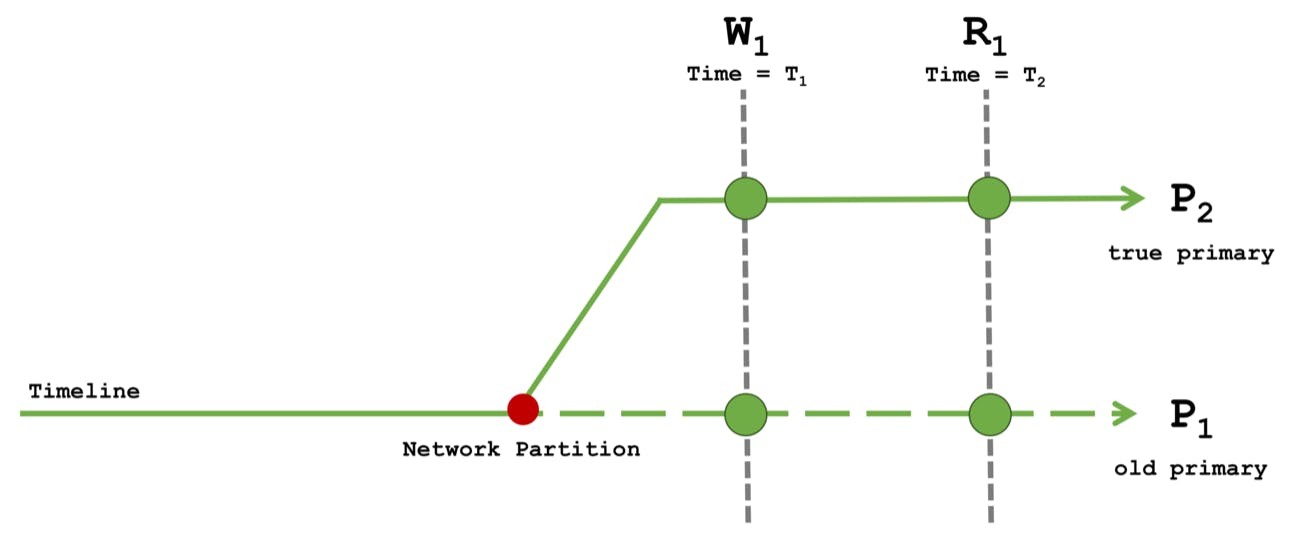
테스트 시나리오

Read Concern majority with Write Concern majority
-
W1 의 Majority Write 작업이 모두 완료 될 때까지, R1는 기다려야함.
- W1의 작업이 완료된 내역을 Read 하기 때문에 R1는 W1 의 결과값을 반환
-
혹시라도 장애가 발생하더라도, 데이터는 보장받기 때문에 속도가 느린 대신 예기치 않은 장애에도 정상적인 데이터를 반환하기 때문에 금융 어플리케이션 같인 주문 거래 등에서 일관성 / 내구성을 모두 확보하기 때문에 활용 가능
Read Concern majority with Write Concern 1
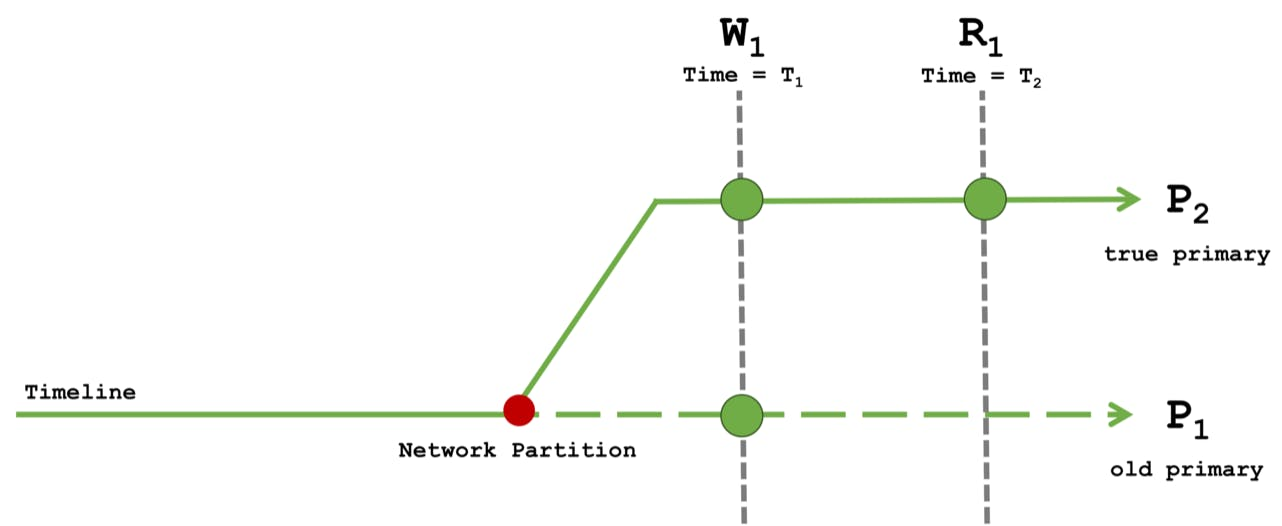
-
W1은 primary에만 성공하면 완료 되기 때문에, w1이 rollaback 되더라도 P1, P2 모두 정상적인 데이터 결과 제공
-
R1은 Majority이기 때문에 T1-W1 작업이 각 secondary에 전파되어 과반수 commit 될 때까지 기다렸다가 정상적이 데이터 확인
-
단, p1 같이 primary가 failover 발생 시 , w1는 primary에만 작성하니 성공적으로 끝나지만, Read majority - R1는 과반수로 전파가 되지 않았기 때문에 읽을 수 없음을 의미
-
장애가 발생할 경우 내구성을 보장하지 않지만, casual 한 순서만 보장
-
사용자 기반에 신속하게 서비스를 제공해야 하는 대규모 플랫폼에 고려.(높은 처리량 트래픽을 관리하고 짧은 대기 시간 요청의 이점, 방금 write한 것은 지연 또는 rollback 이 발생할 수 있기 때문에 글 작성한 유저 등은 일시적으로 아래와 같이 회색 처리하여 write 가 끝나지 않음을 간접적으로 제공)
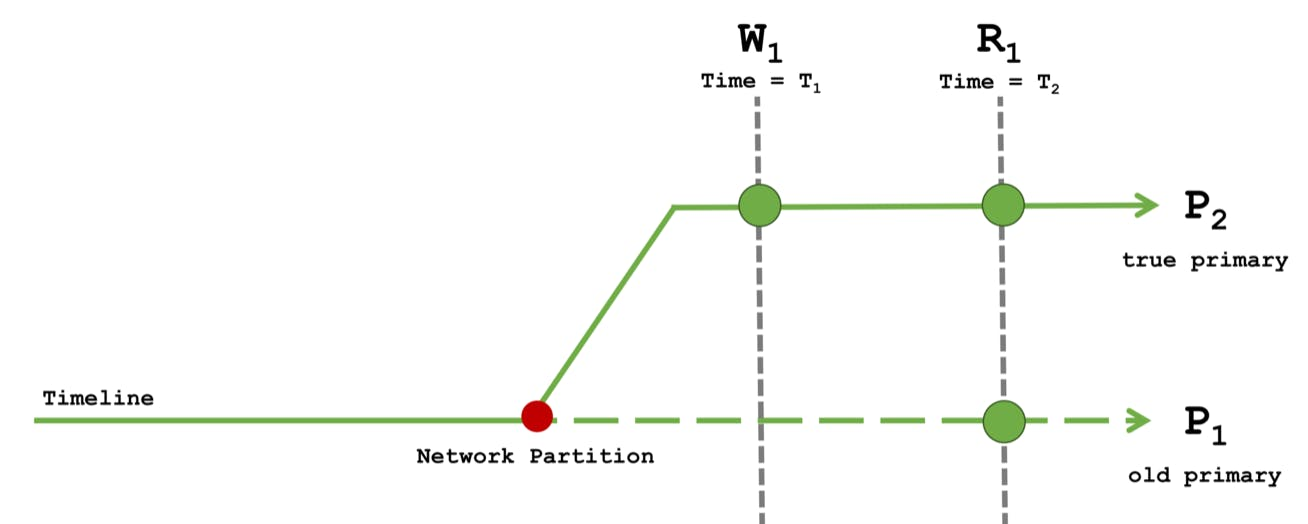
Read Concern local with Write Concern majority
-
Write Concern majority 이기 때문에 과반수 노드에 저장
-
Read 가 local 이기 때문에 P1, P2에서 W1의 commit 되지 않은 데이터를 모두 읽기 가능
- "read your own writes" 보장이 깨지는 현상 발생
- p1, p2에서 여러개의 읽기가 순차적으로 실행 되는 단조로운 경우에도 읽기 순서가 보장되지 않음
- 장애 발생 시 정상적인 데이터가 인과적 보장이 유지되지 않음
- 다양한 제품, 서비스에 대한 리뷰가 있는 사이트에서 유용
- 리뷰를 작성하는 내역에 대해서는 확실한 내구성 보장이 유지되면서, 최신 리뷰 또는 실시간 리뷰를 읽을 경우 write 가 majority라 read를 대기하는 그런 현상이 발생하지 않기 때문에 성능상 이점
- 단, 승인 되지 않은 롤백되는 리뷰도 읽을 수 있는 경우가 발생
Read Concern local with Write Concern 1
-
Write Concern 1이기 때문에 내구성이 부족
- W1에서 write 후 rollback 하더라도, P2/P1 모두 읽을 수 있음
-
Casual read 인 R1의 경우도 P1, P2에서 모두 읽을 수 있음
- "read your own writes" 보장이 깨지는 현상 발생
- p1, p2에서 여러개의 읽기가 순차적으로 실행 되는 단조로운 경우에도 읽기 순서가 보장되지 않음
- 장애 발생 시 정상적인 데이터가 인과적 보장이 유지되지 않음
- 스마트 센서 장치 데이터 수집 같은 높은 쓰기 처리량을 유도하는 곳에서 유용
- 처리량이 높은 워크로드 및 최신성을 선호하는 곳에서 사용
eventual consistency
- 현재 읽고 있는 데이터가 일관되지 않을 수 있지만 결국 일관성이 유지된다는 의미 (최종 동기화)
- 적절한 읽기 문제 없이 클러스터 내 다른 구성원이 읽으면 일관성이 보장 되지 않음
- Secondary에서 readPreference를 사용하여 읽을 경우인데, Primary에서 write 후에 해당 데이터를 secondary 에서 읽을 경우 복제가 완료되지 않아 잘못된 데이터를 읽을 수 있음을 의미
- 하지만 결국은 복제가 완료 되면 제대로 된 데이터를 읽을 수 있음
테스트 할 수 있는 소스가 있어서 공유
https://github.com/MaBeuLux88/mongodb-3.6-demos/tree/master/4-causal-consistency
GitHub - MaBeuLux88/mongodb-3.6-demos
Contribute to MaBeuLux88/mongodb-3.6-demos development by creating an account on GitHub.
github.com
Concern / Preference
- 분산 처리를 기본 아키텍처이기 때문에, 레플리카 셋을 구성하는 멤버들 간의 동기화 제어 가능
- 데이터를 읽고 쓸 때, 필요한 데이터 동기화 수준에 따라 데이터를 변경, 조회할 수 있도록 read concern / write concern 옵션을 제공
- 클라이언트에서 쿼리 단위로도 설정 가능
- 레플리카 셋의 어떤 멤버에게 데이터를 읽을 것인지 설정할 수 있는 read preference 가 존재
Write Concern
- 데이터의 DML 작업에 대해 동기화 수준을 제어
- single / multi document transaction 모두 해당
- 5.0 부터는 majority 가 default / 그전에는 w:1 (primary 만)
- ACKNOWLDGED(default)
- 변경 내용을 메모리상에서만 적용하고 바로 client로 성공 또는 실패 응답 반환
- 동일한 connection 또는 다른 connection 에서 조회 시 변경된 데이터를 메모리 상에서 반환
- 디스크 동기화는 보장되지 않기 때문에 장애 발생 시 손실 위험이 존재
- Journal ACKNOWLDGED
- Journal log (disk) 로 저장하기 때문에 장애 발생시에도 손실 가능성 거의 없음 0.01초?
- 3.6부터는 Journal log 가 항상 자동으로 active 이기 때문에 ACKNOLDGED 와 차이가 없음
- Majority
- 몽고디비는 write 연산이 과반수의 레플리카와 electable 맴버에 적용될 때까지 대기
- write 연산은 primary election이 이벤트가 발생해도 롤백되지 않으며, primary를 포함하여 여기에 포함된 모든 레플리카들의 journal에 적용됨을 보장
Read Concern
- 데이터 읽기를 일관성 있게 유지할 수 있도록 ReadConcern 옵션을 제공
- https://parkcheolu.tistory.com/396
- 4.4 부터는 global 로 replica set / sharded cluster 에 대해서 read concern 설정 가능
- https://www.mongodb.com/docs/manual/reference/read-concern/
https://www.mongodb.com/docs/manual/core/read-isolation-consistency-recency/
https://www.mongodb.com/docs/manual/core/causal-consistency-read-write-concerns/ - 현재 최신화 여부는 oplog 의 적용 정보를 확인하여 결정(Primary 로 보고)
- local
- 최신의 데이터를 반환하는 방식(default) - primary
- 장애 시 데이터가 rollback 되어 phantom read 와 비슷한 상황이 발생
- Casual consistency 를 보장하지 않음
- https://www.mongodb.com/docs/manual/reference/mongodb-defaults/
- Availability
- 최신의 데이터를 반환하는 방식(Sharded Cluster)
- causally consistent sessions and transactions 에서는 사용할 수 없음
- Sharded cluster에서는 읽기 지연이 가장 낮지만, Chunk migration 시 고아 문서(orphaned document)를 반환할 수 있기 때문에 일관성에 문제가 있음 -> local 사용 시 해결 가능
- https://www.mongodb.com/docs/manual/reference/read-concern-available/#mongodb-readconcern-readconcern.-available-
- majority
- 다수의 멤버들이 최신의 데이터를 가졌을 때에만 읽기 결과를 반환
- 클라이언트가 읽었던 데이터가 롤백으로 인해 사라질 가능성은 희박하지만, 일부 멤버들이 동시에 장애 발생시에 phantom read발생 가능성 존재
- linearizable
- 레플리카셋의 모든 멤버가 가진 변경 사항에 대해서만 결과 반환
- 절대 롤백 되지 않음
- Snapshot
- Multi document transaction 에서 사용
Retryable Writes
- https://www.mongodb.com/docs/manual/core/retryable-reads/#retryable-reads 번역한 내용입니다. 참고하세요.
- 네트워크 오류가 발생하거나 장애가 발생하여 replication 또는 sharded cluster 의 primary 를 찾을 수 없는 경우 특정 write 작업을 한 번만 자동으로 재시도
- 네트워크 오류에 대해서는 단 한번만 재시도하며, 지속적으로 네트워크 오류는 해결하지 못함.
- 장애로 인한 failover 경우
- Driver 가 serverSelectionTimeoutMS 동안 기다렸다가 재시도
- 단, 장애조치 시간이 serverSelectionTimeoutMS 초과의 경우 처리하지 않음
- 클라이언트가 쓰기작업을 실행한 후 localLogicalSessionTimeoutMinutes 이상 응답하지 않을 경우 다시 시작하지 않고, 응답을 시작할 때 쓰기 작업이 재시도 되어 적용
- 전제 조건
- Supported Deployment Topologies
- sharded cluster / replication 환경에서만 되며, standalone 은 해당되지 않음
- Supported Storage Engine
- Wiredtiger 엔진 또는 memory storage engine 과 같은 document lock 수준의 storage engine 만 가능
- 3.6+ MongoDB Drivers
- 3.6 mongodb driver 이상에서만 지원
- 4.2 + MongoDB Drivers
- Retryable Write 가 enable 이 default (false 로 하고 싶으면 retryWrites=false 로 명시)
- Supported Deployment Topologies
- Retryable Writes and Multi-Document Transactions
- 4.0
- Transaction 내에서 commit 또는 rollback 시 write 를 재시도 진행 (Driver 에서 retryWrite 가 false 라고 해도 다시 한번 진행)
- Trnasaction 내의 각각의 명령어들에대해서는 retryWrite 설정값과 상관없이 개별적으로 재시도는 할 수 없음
- Retryable Write 명령어
- https://www.mongodb.com/docs/manual/core/retryable-writes/#retryable-write-operations 참고
- 4.2 부터 shard key 도 업데이트 가능 (Transaction 내)
- v4.2 부터 중복 키 예외가 발생한 single document에 대해서는 upsert 를 재시도 (v4.2 이전에는 중복키 오류에 대해서는 upsert 작업을 재시도 하지 않음)
- upsert retryable write 조건
- unique index 가 존재
- unique index 값을 수정하려는 경우는 안됨 (반드시 검색하는 내용이 유니크 값으로 검색해야 함)
- unique 가 아닌 값으로 검색하는 경우도 해당 되지 않음.
- singe equality 또는 logical and + equality 명령어 경우
- unique index 가 존재
- upsert retryable write 조건

Retryable Reads
- https://www.mongodb.com/docs/manual/core/retryable-reads/#retryable-reads 번역
- MongoDB Driver가 네트워크 오류가 발생하거나 장애가 발생한 경우 read작업을 한 번만 자동으로 재시도
- 전제조건
- MongoDB Server가 4.2 이상인 경우, 이와 호환되는 Driver를 사용하는 경우 재시도 읽기 가능 (공식)
- 하지만, Mongo Server는 3.6 이상인 경우도 가능
- 재시도 가능한 읽기
- 4.2 부터는 retryable read 가 default 가 enable
- retryReads=false 로 비활성화도 가능하지만, mongosh 에서는 지원하지 않음
- Retryable Read 명령어
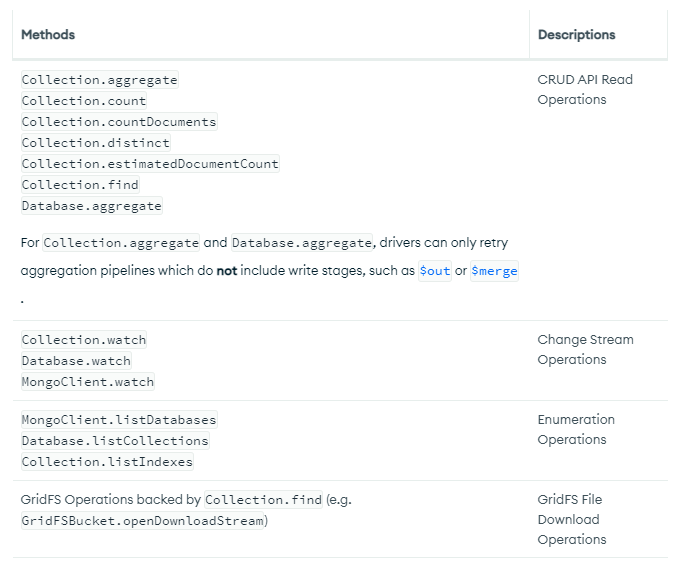
- 지원되지 않는 명령어
- db.collection.mapReduce()
- getMore
- database.runCommand 로 실행한 모든 읽기,쓰기 명령어는 지원되지 않음
- 동작
- 잦은 네트워크 에러
- retryable read는 단 한번만 재시도 하기 때문에, 일시적인 네트워크 에러에는 도움이 되나, 영구적인 네트워크 에러는 해결해주지 않음
- Failover period (failover 발생하는 동안)
- Driver는 read preference 를 사용하여 read 명령어를 실행
- 만약 read preference에 의해 read를 하려고 할 때, 재시도할 서버를 선택할 수 없는 경우 오류 발생
- driver는 serverSelectionTimeoutMS 의 ms 값 만큼 failover 가 완료 될 때까지(정상화) 서버 선택을 기다림
- serverSelectionTimeoutMS 만큼 기다려도 retryable read를 할 적절한 서버가 없다면 읽기를 처리하지 않음
- 잦은 네트워크 에러
Global Logical Clock
- https://www.mongodb.com/blog/post/transactions-background-part-4-the-global-logical-clock
- MongoDB의 동기화를 강화
- 하이브리드 Logicla Clock 으로 구현되어 암호화로 보호되며, Global Logical Clock 은 Shard Cluster 전체에 걸쳐 동작
- Multi document ACID Transaction 에서는 Global snapshot을 생성할 수 있으므로, 일관된 global view에서는 시간이 필수.
- 배경
- MongoDB의 Clock 은 Shard Mongodb 내 primary oplog 에서 추적
- 각 작업은, 지속적으로 변경되는 데이터를 oplog 에 저장
- 각 명령어가 기록되고, primary 와 clock 시간이 logical clock 에 '연결'하고 oplog에 명령어와 함께 저장 (oplog 에 timestamp 뿐만 아니라, logical clock이 함께 연결로 이해)
- 해당 작업은 oplog에 순서를 제공하고, 샤드 내 모든 노드들에 동기화 하는데 사용
- 하이브리드 logical clock
- 샤드 내 노드들만의 자체 clock 이 있을 수 있지만, cluster 내에서는 동작하지 않음
- clock 은 클러스터 내에서 서로 참조 하지 않는 단순 증가만 할 뿐
- 3.6에서 구현된 하이브리드 logical clock을 입력하면, 해당 하이브리드 클락은 시스템 시간 뿐만 아니라 동시에 발생하는 명령의 카운터와 결합하여 물리적인 동일한 timestamp를 생성
- 새로운 timestmp는 클러스터 내 모든 session 에 대해 적용
- 서버가 timestamp가 포함된 message를 받을 때, 만약 timestamp가 노드의 현재 timestamp 보다 이후이면, timestamp는 최신의 timestamp 값으로 변경 진행되며, 새로운 변경 과 함께 적용된 최신 timestamp로 갱신이 이루어짐
- 조작 방지
- 공격자가 시스템에 시간을 조작하여 데이터를 추가를 할 수 있는데, 이 때 최신 timestamp 값 보다 늦은 값이면, 샤드는 이러한 것을 막아 추가가 안되도록 함
- 해당 문제는 primary의 private key를 이용하여 hash된 timestamp로 생성하여 migration 진행
- 해당 hash는 timestamp소스가 cluster에 의해 이루어진 verify 내에 있는지 확인용으로 사용되며, 혹시라도 공격자가 private key를 사용할 수 있으면 해당 시스템은 광범위하게 손상이 발생 가능성이 존재
- Global Logical clock 와 Transaction
- 하이브리드 Logical Clock을 사용하면 replication 의 여러 노드 및 cluster 의 shard node 간의 쉽게 동기화가 가능
- Transaction 범위가 4.2 부터 sharded cluster 로 확대되었기에, 신뢰성 높은 clock 동기화가 중요하며 기본이 되어야 가능함
- Clock 을 조작하기 힘든 것이 신뢰성을 높이는 효과
아직도 추가할 내용이 많음에도 불구하고 대부분 내용들이 번역기를 돌려 이해한 내용들을 바탕으로 작성한 것이라 부족한 부분이 많아 추가하지 못했습니다.
관련된 내용들도 정리하여 추가로 올리도록 하겠습니다.
해당 내용들 중에 잘못된 내용들이 있을 수 있으니 참고 정도로만 해주시고, 중간 중간 mongodb 공홈에서 자세한 내용을 읽어 보시면 좋을 듯 합니다.
'MongoDB' 카테고리의 다른 글
| [MongoDB] tcmalloc memory cache 정리 (0) | 2022.08.22 |
|---|---|
| [MongoDB] taskExecutorPoolSize (0) | 2022.08.08 |
| [MongoDB] Replica Set to StandAlone (v4.2) (0) | 2022.07.04 |
| [MongoDB] Upgrade 이슈 (4.0 to 4.2) - MinValidDocument.oplogDeleteFromPoint is an unknown field (0) | 2022.07.02 |
| [MongoDB] 3.4 to 4.2 upgrade (rpm) (0) | 2022.07.02 |