기본적인 명령어
- runCommand
- tool 에서 많이 보인 command
- 지정한 DB에서 도우미를 제공해 주는 명령어
- document 또는 String type
- Database 명령어로 문자열 또는 Document 형태의 명령어로 반환 또한 Document, string으로 반환
- 동작방식
- db.runCommand()는 현재 선택된 DB 에서만 명령을 실행
- 일부 명령은 admin DB에서만 적용되며, 이러한 명령을 실행하기 위해서는 admin 으로 변경하거나 adminCommand()를 사용
- 명령 결과
|
Field |
Description |
|
ok |
명령 성공 실패의 여부를 표시 |
|
operationTime |
수행된 작업 시간 oplog 항목의 Timestamp로 MongoDB에 표시 Replica set 과 Shard cluster 에 해당
만약,명령어가 oplog 항목을 생성하지 않는 경우 ex) 읽기 작업의 경우, 해당 항목을 표시하지 않음 이때 운영 시간을 반환
Read concern을 "majority"와 "loinearizable" 인 경우, timestamp를 oplog의 가장 최근에 완료된 항목 값을 사용. Consistent session과 관련된 작업의 경우, MongoDB Driver는 Read 작업과 클러스터 시간을 자동으로 설정하여 사용 (v3.6) |
|
$clusterTime |
적용된 cluster 시간을 반환 cluster time은 작업 순서에 사용되는 논리적인 시간 Cluster와 replica set일 경우에 해당하며, Mongodb 내부 동작에서만 사용 |
ex)
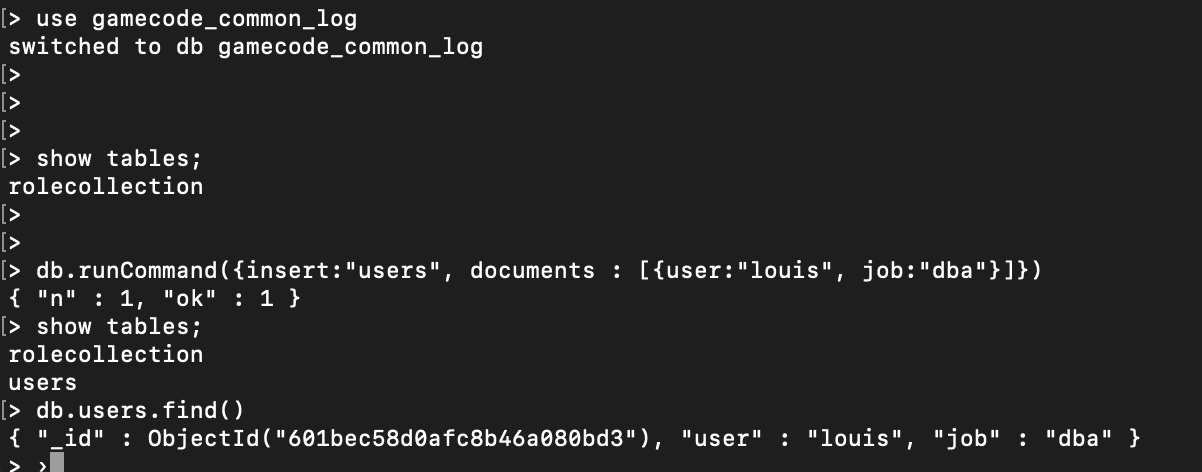
참고 : https://docs.mongodb.com/manual/reference/method/db.runCommand/
https://docs.mongodb.com/manual/reference/command/
https://docs.mongodb.com/manual/reference/command/insert/#dbcmd.insert
- Database
- Database 생성 방법
- USE 구문을 사용해서 생성 가능
- USE 구문을 사용하면 DB선택도 가능
- 하지만, 단순 빈 Database 는 생성 하더라도 다시 확인 시 보이지 않음( mongo> show dbs )
- 하나의 Document 를 추가해 줘야 database가 생성 된 것을 확인 가능
- Collection (Table) 생성 방법
- 생성하는 방법은 2가지가 존재 하지만, 특별한 상황이 아니라면 Document를 추가(insert)하여 collection이 생성 되도록 진행
- createCollection을 이용한 명시적 생성은 Collection의 세부 정보를 수정할 수 있기에, 잘 알고 사용하지 않을 경우 예상 치 못한 장애를 발생 시킬 수 있기에, 미연에 방지하고자 하기 위함
- 4.2부터는 MMAPv1 Storage engine과 그에 대한 createCollection에서 사용 가능한 option도 삭제
- Show collections 로 collection 리스트 확인 가능 ( mongo> show collections )
- 지향 : db.컬레션명.insert()
- Ex) people이라는 Collection 추가 및 name, age 필드 추가
- db.people.insert({"name":"Louis.Kim"},{"age":36})
- 지양 : db.createCollection("people") 또는 db.createCollection("people",{Option 및 Option 값})
- CreatedCollection
- capped Collection
- db.createCollection(<컬렉션명>, {capped : true, size:4096})
- 일반 collection 과 다르게, 정해진 크기를 초과하게 되면 자동으로 가장 오래된 데이터를 삭제
- 반대로 유저가 임의로 데이터를 삭제는 불가능
- 삭제를 하고자 한다면, drop 만 가능
- 원형 버퍼와 유사한 방식으로 동작
- Capped Collection의 대안으로 MongoDB의 TTL 인덱스 고려 가능
- Collection 에 TTL를 설정하여 Expire 데이터를 제거 가능.
- Capped Collection 는 TTL index 와 호환되지 않음
- Sharding 지원하지 않음
- Aggregation pipeline 단계의 $out 를 capped collection의 결과를 wirte 할 수 없음
- size는 byte 단위
- 최소 size는 4096 byte (Collection이 기본으로 차지하는 size 때문)
- Document의 삽입 속도가 매우 빠름
- order를 하지 않은 collection을 find하는 경우, Insert 한 순서대로 결과를 가져오기 때문에 순서 보장하기에 매우 빠름
- 가장 최근에 삽입된 요소를 효율적으로 검색 가능
- 크기를 지정하고 사용하므로 추가 공간 필요 없음
> db.createCollection(name, {capped: <Boolean>, autoIndexId: <Boolean>, size: <number>, max <number>} )
|
파라미터 |
타입 |
설명 |
|
name |
string |
생성할 도큐먼트의 이름 |
|
options |
document |
컬렉션의 옵션 부여 |
option
|
필드 |
타입 |
설명 |
|
capped |
boolean |
capped이면 "true"를 아니면 "false"를 할당 |
|
autoIndexId |
boolean |
capped이면 "true"를, 그 외에는 "false"를 할당 |
|
size |
number |
저장 공간의 크기 지정 |
|
max |
number |
저장할 도큐먼트의 최대 개수 지정 |
|
혼자만의 고민 capped Collection > 만약 100일치의 데이터를 보관이 정책인데, 들어가는 데이터 size가 크면 100일치 보다 더 일찍 삭제 될꺼고, size가 작으면 100일 치 보다 더 많이 남아 있을 껀데....??? > 차라리 storage 공간이 한정적이라서 중요하지는 않지만 보관이 필요한 경우 한정된 자원속에서만 저장이 필요한 경우, 관리 포인트를 없애기 위해 사용... > 하지만 데이터가 지속적으로 삭제 추가 되는 상황이라면 I/O도 꾸준히 있을듯....여러모로 사용을 안하는 것이.. > 로그 데이터나, 일정 시간 동안만 보관하는 통계 데이터를 보관하고 싶을 때 유용할 것 같음. |
- view
- 미리 설정한 내용에 대해 읽을 수만 있는 뷰
- 실제로 데이터를 저장해서 불러오지 않기 때문에 사용할 수 있는 명령어에 제약(집계 파이프라인의 문법을 이용)
-
Document
- [Delete]
- Delete(권장)
- 3.2부터 Remove를 대체하는 메소드 추가
- db.컬렉션명.deleteMany(조건)db.employee.deleteMany({"name":"Louis.Kim"})
- Ex) employee 컬렉션에서 name이 Louis.Kim 을 삭제
- db.컬렉션명.deleteOne(조건)
- 해당 조건에 맞는 한건만 삭제
- Remove(지양)
- db.컬렉션명.remove(조건)
- deleteMany 와 remove 차이는 거의 없지만, 앞으로 remove는 지원하지 않는다고 예정하고 있기에 deleteMany로 삭제 진행 권장
- 추가로, 한 건만(유일값 이라고 단정 지을 수 있다면) 삭제 한다면 deleteOne이 deleteMany보다 성능이 미세하지만 더 낫기에 상황에 맞게 사용하면 됨(Single Transaction 처리냐, Multi Transaction 차이 여부)
- [Update]
- 권장
- Update 진행 시 대소문자 구분하여 검색 및 업데이트 진행
- 여러건의 Update가 아니라면, 무분별하게 Multi 옵션을 사용하지 않는 것을 추천.
- explain을 확인하여 Index 사용 여부를 확인하며, _id를 이용한 검색을 활용
- save 명령어는 지양 (insert / update 모두 해당)
- Update이 후 존재하지 않으면 Insert하는 경우에만 upsert Option을 이용하며, 그게 아닌 곳에서는 Insert / Update를 명시해서 사용
db.collection.update(
{찾을 조건},
{$set:{변경할 필드 내용}}
, {
upsert: <boolean>, // 업데이트할 내용이 없다면 새로운 Document추가, Default는 False로 없으면 업데이트 안함
multi: <boolean>, // 여러건 업데이트 여부, Default는 False로 한건만 업데이트
writeConcern: <document>,
Collation: <document>, // 3.4
arrayFilters: [ <filterdocument1>, ... ], //3.6
hint : <document | string>. // Mongodb 4.2
} // Option 생략 가능
)
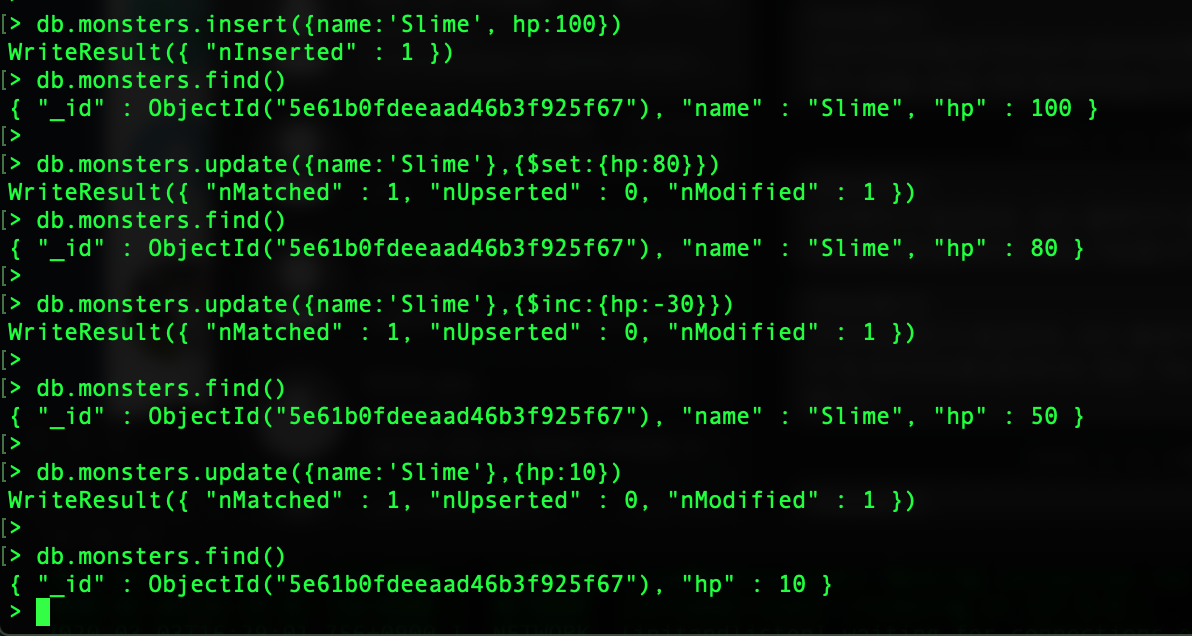
- db.collection명.update({조건}, {$set:{변경하고자 필드내용}})
- Monster Collection에서 Slime의 hp를 30으로 변경// WriteResult({ nMatched: 1, nUpserted: 0, nModified: 1 });
- db.monsters.update({ name: 'Slime' }, { $set: { hp: 30 } });
- 만약 $set을 추가 하지 않고 진행 시 전부 지워지고 {변경하고자 필드 내용}만 남음
- db.monsters.update({ name: 'Slime' }, { hp: 30 } );
- 이렇게 하면 결과는 hp:30만 남고 모든 내용 삭제 됨
- 추가 $inc 를 사용하여 기존 데이터를 손쉽게 제어 가능
- Slime의 hp를 현재 얼마인지 몰라도 -30 해보자// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
- - db.monsters.update({name:'Slime'},{$inc:{hp:-30}})
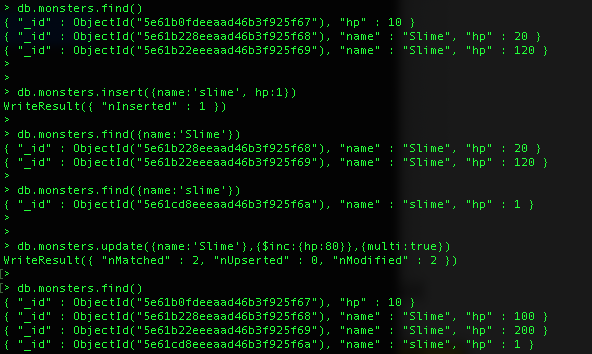
- Update를 해야하는 것이 한건이 아니라 여러건인 경우 multi Option을 추가해 줘야함
- (Multi Option 을 추가 하지 않는 경우 한건만 변경)// WriteResult({ "nMatched" : 2, "nUpserted" : 0, "nModified" : 2 })
- > db.monsters.update({name:'Slime'},{$inc:{hp:-80}},{multi:true})
[Update - Option]
|
Parameter |
Type |
설명 |
|
upsert |
boolean |
Optional. (기본값: false) 이 값이 true 로 설정되면 query한 document가 없을 경우, 새로운 document를 추가 |
|
multi |
boolean |
Optional. (기본값: false) 이 값이 true 로 설정되면, 여러개의 document 를 수정 |
|
writeConcern |
document |
Optional. wtimeout 등 document 업데이트 할 때 필요한 설정값 기본 writeConcern을 사용하려면 이 파라미터를 생략 |
|
Collation |
document |
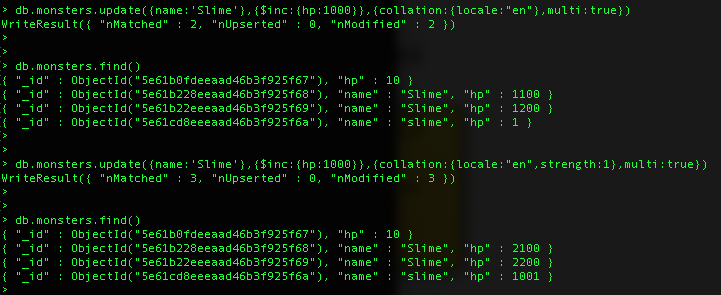
데이터 정렬을 지정 : 데이터 정렬을 사용하면 소문자 및 악센트 표시 규칙과 같이 문자열 비교를 위한 언어별 규칙을 지정할 수 있음. 한국어는 필요한지 의문(대,소문자 악센트 등의 규칙이 없음) 다국어 지원시 고려해 봐야 될 부분 collation: { locale: <string>, // 해당국가 언어 특성 적용( caseLevel: <boolean>, caseFirst: <string>, strength: <int>, // 1: 대소문자 구문 안함(default :0 대소문자구분) numericOrdering: <boolean>, alternate: <string>, maxVariable: <string>, backwards: <boolean> }
|
|
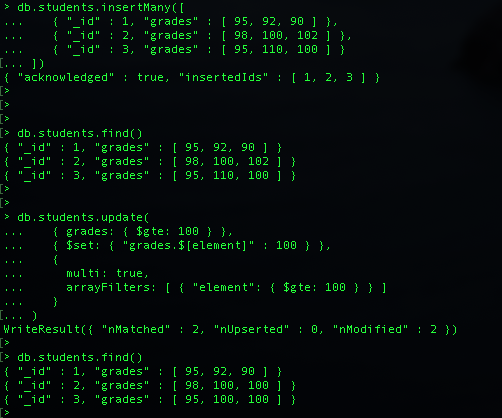
arrayFilters |
Array |
Array Filter에서 업데이트 작업을 위해 수정해야할 배열 요소를 결정하는 설정 $[<조건>]를 사용하여 조건 지정
|
|
Hint |
Document or string |
Index 를 강제로 지정 가능 Ex) status index를 강제로 사용
db.members.createIndex( { status: 1 } ) db.members.createIndex( { points: 1 } )
db.members.update( { points: { $lte: 20 }, status: "P" }, // Query parameter { $set: { misc1: "Need to activate" } }, // Update document { multi: true, hint: { status: 1 } } // Options ) |
[Update]
[Multi - Option Test]

[Collation - 대소문자 비교]
- 기본적으로 대소문자 구분
- Collation의 strength 을 적용 후 진행
[arrayFilters]

- Find
- Find 관련 명령어에는 여러개가 있으며, 그 중에 많이 사용하는 위주로 가이드 하며, 필요 시 추가 가이드 진행 예정
- Find명령어 사용 시 필요한 filed 명을 사용하여 검색을 추천
- Ex) db.bios.find( {조건}, {_id:0, name:1 , money:1})
- 만약 empno만 빼고 다 보고자 하면 그때는 > db.thing.find( { }, {empno: 0} ) 이런식으로 표시
- _id에 대해서만 혼용 사용 가능하며, 다른 필드들에 대해서는 1과 0을 혼용해서 표시 안됨
- 조건 검색 시 가급적 _id를 작성하며 Range 검색 시 기간을 지정하여 검색 추천
Ex) db.bios.find( {"_id":{"$gte":ObjectId("5dfaf5c00000000000000000", "$lte":ObjectId("5dfaf5c00000000000000000")}, {_id:0, name:1 , money:1})
(오늘 이전 모든 데이터 검색 or 오픈 이후 모든 날짜에 대해 검색 같은 전체 검색은 지양, 어제부터 일주일 전, 현재부터 하루 전 데이터 식으로 검색을 추천) - filed 명시 방법
> db.thing.find( { }, {empno: 1} )
// empno 를 표시하고, _id는 default로 표시, 단 그 외(ename) 은 표시 안함
> db.thing.find( { }, {empno: 0} )
// empno 만 표시를 안하고 나머지 ename , _id는 표시
> db.thing.find( { }, {_id:0, empno: 1} )
// empno만 표시하고, _id 및 다른 필드는 표시 안함.
// 여기서 중요한건 _id는 항상 명시해 줘야 하며, 보고 싶은 필드만 1로 설정해서 표시
// 다른 필드의 경우 ename이 있더라도 ename:0 으로 하면 에러 발생 >> 왜?????
> db.thing.find( { }, {empno: 1, ename:0} )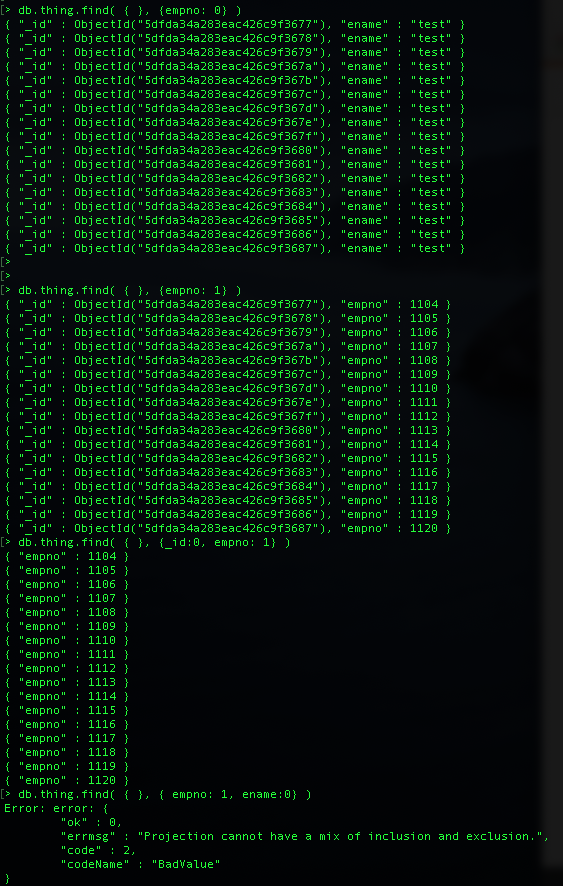
|
명령어 |
내역 |
|
find() |
검색 |
|
findAndModify() |
검색 후 수정 Update, upset, remove 모두 가능 new : true를 설정하여 update 이후 값을 리턴 new : false 또는 미적용 시 update 이전 값을 리턴
db.monsters.findAndModify({ query: { name: "Dragon" }, update: { $inc: { att: 1000 } ,$set :{"name":"Dragon","hp":4000,"att":1000}}, upsert: true, new : true }) |
|
findOne() |
한건만 검색 |
|
findOneAndDelete() |
한건만 검색 후 삭제 |
|
findOneAndReplace() > v3.2 |
한건만 검색 후 변경 returnNewDocument : true 설정하여 변경 전후 확인 가능 Replace 와 Update의 경우 Update는 명시한 필드만 변경 되지만, Replace의 경우는 명시한 필드 변경 외에는 나머지 필드는 모두 삭제 됨 가급적이면 Update만 사용 해야함 |
|
findOneAndUpdate() > v3.2 |
한건만 검색 후 변경 returnNewDocument : true 설정하여 변경 전후 확인 가능 |
[findAndModify]
db.monsters.findAndModify({ query: { name: 'Demon' }, update: { $set: { att: 350 } }, new: true })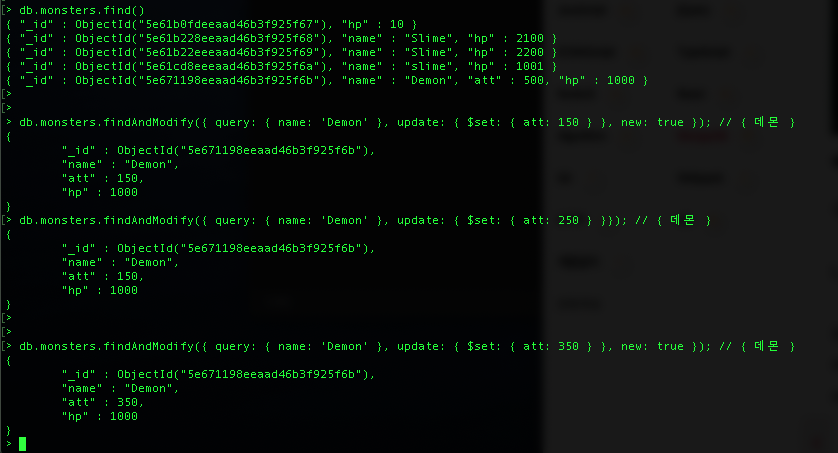
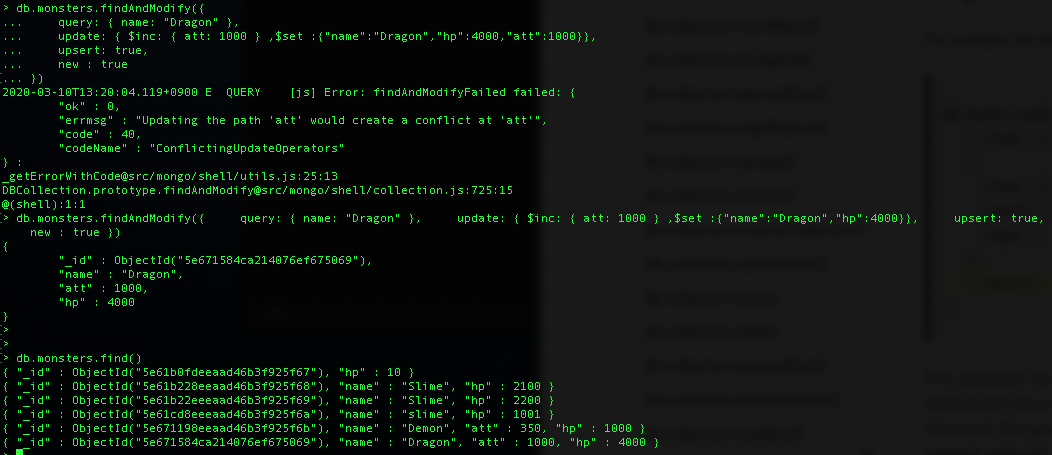
[findAndModify]
db.monsters.findAndModify({
query: { name: "Dragon" },
update: { $inc: { att: 1000 } ,$set :{"name":"Dragon","hp":4000,"att":1000}},
upsert: true,
new : true
})
- Cursor
- 쿼리 결과에 대한 포인터
- find 명령어는 결과로 Document를 반환하지 않고 Cursor를 반환(Pointer)
- 성능을 높이기 위함(결과 값을 리턴하는 것이 아닌 값의 결과들을 모아 놓은 주소를 반환한다고 이해)
- 커서는 일시적으로 결과를 읽어내려고 존재하기 때문에 10분의 제한시간 이후에는 비활성 상태 전환
- find 명령어를 실행하면 batch 라는 곳에 검색한 결과를 저장
- 일반적으로 101개의 document 를 batch에 모아 놓고 20개씩 커서가 가르킴
- 한 개의 document를 불러오기 위해서는 next()로 호출
- 커서로 batch 에 102번째 document를 불러오려고 하면 batch에 쿼리 결과를 102번째부터 시작해서 총 101개를 담고, 102번째 Document를 cursor 가 가르킴
- 커서를 이용한 Document 반환
- find 명령어 모든 document를 모두 불러오기 위해서는 toArray() 메소드를 이용하면 모든 정보를 가져올 수 있음
> var cursor = db.cappedCollection.find()
> cursor
> db.cappedCollection.find()
결과...
> cursor.next()
하나만 리턴?
> cursor.hasNext()
true- 모든 document 가져오는 방법
> db.cappedCollection.find().toArray()
- toArray() 메소드 특징은 find문의 모든 결과를 담은 배열을 반환
- 모든 값이 다 필요하지 않다면 toArray 메소드는 비효율적
- Document 총 크기가 매우 크다면 toArray 메소드를 사용할 시 사용 가능한 메모리 용량을 초과해 버릴 수 있음
- forEach 메소드를 이용하여 커서로 각각의 Document를 순차적으로 불러와서 작업 가능 (메모리 효율적인 사용 가능)
- https://docs.mongodb.com/manual/reference/method/js-cursor/
[그 외]
- Terminate Running Operations
- maxTimeMS()와 db.killOp() 으로 실행 중인 작업을 종료(kill) 가능
- MongoDB 배치에서 작업의 동작을 제어하기 위해 필요에 따라 해당 작업을 사용
- maxTime MS
- 작업 시간 제한을 설정
- 작업이 지정된 시간 제한인 maxTimeMS() 에 도달하면, MongoDB가 다음 interrupt 지점에서 작업을 중단
- 샘플
- 중단 쿼리 설정
- mongo shell에서 , 쿼리의 시간을 30 ms 으로 설정
- location collection 에서 town이라는 필드에 대해 maxTimeMS를 30 ms 설정
db.location.find( { "town": { "$regex": "(Pine Lumber)", "$options": 'i' } } ).maxTimeMS(30)
- 중단될 명령어 실행
- 잠재적으로 오래 실행될 것이라는 명령어 실행
- city key가 존재하는 각각의 개별 collection 필드를 반환하는 명령어 실행
db.runCommand( { distinct: "collection", key: "city" } )
- maxTimeMS 를 45ms으로 필드에 대해 추가도 가능
db.runCommand( { distinct: "collection",key: "city",maxTimeMS: 45 } )
- db.getLastError() 와 db.getLastErrorObj()으로 중단된 옵션에 대한 오류를 반환
- KillOp
- db.killOp() 는 작업 ID로 실행 중인 작업을 kill
- 명령어 : db.killOp(<opId>)
- 해당 명령어는 클라이언트를 종료할 뿐이지, DB 내부에서는 해당 명령어는 작업 종료 안함?
- Sharded Cluster
- MongoDB4.0에서 부터는, mongos 에서 KillOp 명령을 사용하여 Cluster 내 shard에 걸쳐서 실행되고 있는 쿼리를 kill 할 수 있음(read 작업).
- Write 작업에 대해서는, mongos에서 killOp 명령어로 각 샤드에 존재하는 쿼리를 kill 할 수 없음.
- Shard 에 대해서는 아래 참고
- 샤드 작업 리스트 확인 : Mongos에서 $currentOp의 localOps를 참고
[참고]
https://www.zerocho.com/category/MongoDB/post/579e2821c097d015000404dc
https://docs.mongodb.com/manual/reference/method/db.collection.update/
https://docs.mongodb.com/manual/reference/collation-locales-defaults/
https://cinema4dr12.tistory.com/373 (capped collection)
https://velopert.com/479 find 관련한 상세한 설명
'MongoDB > MongoDB-Study_완료' 카테고리의 다른 글
| [MongoDB] [Study-6] MongoDB CRUD 쓰기 연산 (0) | 2021.03.28 |
|---|---|
| [MongoDB] [Study-Break] Cursor 간략한 정리 (0) | 2021.03.27 |
| [MongoDB][Study-3] Sharding (0) | 2021.03.27 |
| [MongoDB] [Study-2-2] P-S-A 구성 (0) | 2021.03.27 |
| [MongoDB] [Study-2-1] Wired Tiger (WT엔진) (0) | 2021.03.27 |