샘플 데이터
- "맛있는 MongoDB"
- 샘플 데이터 공유
$ git clone https://github.com/Karoid/mongodb_tutorials.git
$ ec2-user@mongodb:~$ cd mongodb_tutorials/car_accident/
ec2-user@mongodb:~/mongodb_tutorials/car_accident$ mongoimport -d car_accident -c area --file area.json
2021-03-02T13:29:00.380+0000 connected to: localhost
2021-03-02T13:29:00.403+0000 imported 228 documents
ec2-user@mongodb:~/mongodb_tutorials/car_accident$
ec2-user@mongodb:~/mongodb_tutorials/car_accident$ mongoimport -d car_accident -c by_month --file by_month.json
2021-03-02T13:29:32.252+0000 connected to: localhost
2021-03-02T13:29:32.309+0000 imported 227 documents
ec2-user@mongodb:~/mongodb_tutorials/car_accident$
ec2-user@mongodb:~/mongodb_tutorials/car_accident$ mongoimport -d car_accident -c by_road_type --file by_road_type.json
2021-03-02T13:29:50.266+0000 connected to: localhost
2021-03-02T13:29:50.309+0000 imported 227 documents
ec2-user@mongodb:~/mongodb_tutorials/car_accident$
ec2-user@mongodb:~/mongodb_tutorials/car_accident$ mongoimport -d car_accident -c by_type --file by_type.json
2021-03-02T13:30:08.372+0000 connected to: localhost
2021-03-02T13:30:08.408+0000 imported 687 documents
> show dbs
admin 0.000GB
car_accident 0.000GB
config 0.000GB
local 0.000GB
test 0.000GB
>
> use car_accident
switched to db car_accident
> show tables
area
by_month
by_road_type
by_type
- Find 관련 명령어에는 여러 개가 있으며, 그 중에 많이 사용하는 위주로 가이드 하며, 필요 시 추가 가이드 진행 예정
|
명령어 |
내역 |
|
find() |
검색 |
|
findAndModify() |
검색 후 수정 Update, upset, remove 모두 가능 new : true를 설정하여 update 이후 값을 리턴 new : false 또는 미적용 시 update 이전 값을 리턴
db.monsters.findAndModify({ query: { name: "Dragon" }, update: { $inc: { att: 1000 } ,$set :{"name":"Dragon","hp":4000,"att":1000}}, upsert: true, new : true }) |
|
findOne() |
한건만 검색 |
|
findOneAndDelete() |
한건만 검색 후 삭제 |
|
findOneAndReplace() > v3.2 |
한건만 검색 후 변경 returnNewDocument : true 설정하여 변경 전후 확인 가능 Replace 와 Update의 경우 Update는 명시한 필드만 변경 되지만, Replace의 경우는 명시한 필드 변경 외에는 나머지 필드는 모두 삭제 됨 가급적이면 Update만 사용 해야함 |
|
findOneAndUpdate() > v3.2 |
한건만 검색 후 변경 returnNewDocument : true 설정하여 변경 전후 확인 가능 |
[Find]
- Find명령어 사용 시 필요한 filed 명을 사용하여 검색하시기 바랍니다.(Covered Query)
- Ex) db.bios.find( {조건}, {_id:0, name:1 , money:1})
- 쿼리가 요구하는(리턴되는) 내용의 모든 필드가 하나의 Index에 포함되어 있으므로, Index만 조회하기 때문에 Document를 조회하는 것보다 훨씬 빠름(일반적으로 인덱스 키는 RAM에 적재되 있거나 디스크에 순차적으로 위치 하기 때문)
- _id 필드를 0으로 명시하지 않는 경우, 결과 값에서 표현이 되기 때문에, covered query 조건이 되지 않으므로, 반드시 _id 필드를 0으로 명시
- 쿼리에 필드가 없거나 필드의 값이 null 이 되면 안된다. i.e. {"field" : null} or {"field" : {$eq : null}}
- v3.6 부터 embedded document의 경우도 적용 (이전 버전 에서는 불가능?)
- db.userdata.find( { "user.login": "tester" }, { "user.login": 1, _id: 0 } )
- 테스트 결과 안되요ㅠ(알고 계신 분 알려주세요)
- 제한
- Geospatial Index 에서는 사용 못함
- Multikey Index에서 배열 필드에 대해서는 Covered index 가 불가능(v3.6부터 non-array field들에 대해서는 사용 가능)
- Covered Query
- field 명시 방법
- 필드에 _id 여부는 항상 명시해야 함(_id를 쿼리 결과 내에서 표현하거나 표현하지 않는 것에 대해 명시를 반드시 해야 함)
- _id에 대해서만 혼용 사용 가능하며, 다른 필드들에 대해서는 보여 주고 싶은 것에 대해서만 1로 명시, 0으로 명시하면 에러 발생
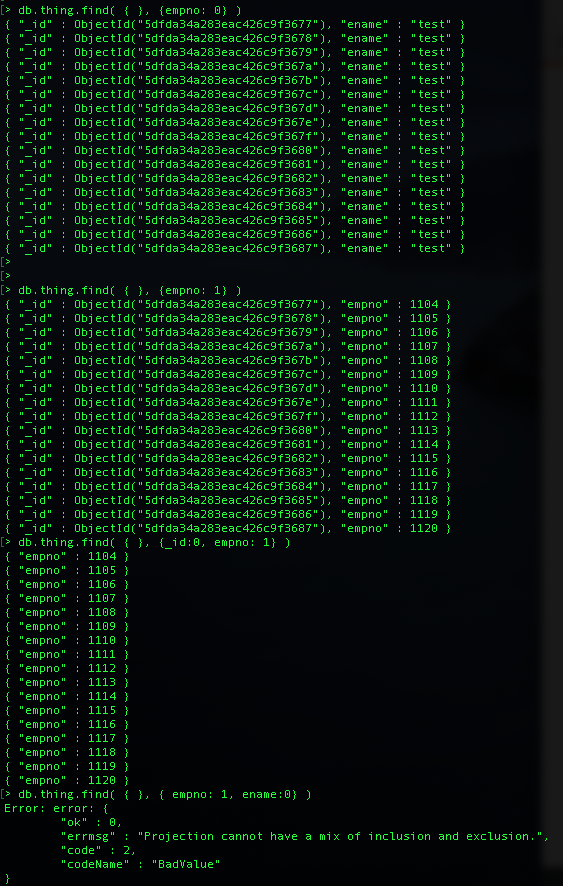
- Ex ) > db.thing.find( { }, {_id:0, empno: 1} ) // empno만 표시하고, _id 및 다른 필드는 표시 안함. // 여기서 중요한건 _id는 항상 명시해 줘야 하며, 보고 싶은 필드만 1로 설정해서 표시 // 다른 필드의 경우 birth 필드가 있더라도 birth:0 으로 하면 에러 발생...왜???모르겠음
- 만약 empno만 빼고 다 보고자 하면 그때는 > db.thing.find( { }, {empno: 0} ) 이런 식으로 표시
- 보고 싶은 field가 있다면, field를 명시할 때 보겠다는 field 들만 명시를 하고,field 명시 여부를 혼용해서 명시하게 되면, 에러가 발생
- 반대로 보고 싶지 않은 field가 있다면 명시 안하겠다는 field 들만 명시를 해야 함
[Filed]
- Covered Query Test
# semester 에 대한 Index 확인
> db.employee.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_"
},
{
"v" : 2,
"key" : {
"semester" : 1
},
"name" : "semester_1"
}
]
# _id 필드를 명시적으로 0 처리 하지 않으면, 자연스럽게 _id 필드도 같이 표시되기 때문에 명시적으로 _id 필드를 표시 안한다고 해야, Convered query 적용 여부를 확인 가능
> db.employee.find({semester:3},{_id:0, semester:1}).explain()
# 필드를 표시 안하게 되는 경우 _id 필드가 표현 되기에 covered query가 되지 않음
> db.employee.find({semester:3},{"field" : null}).explain()# covered index 확인
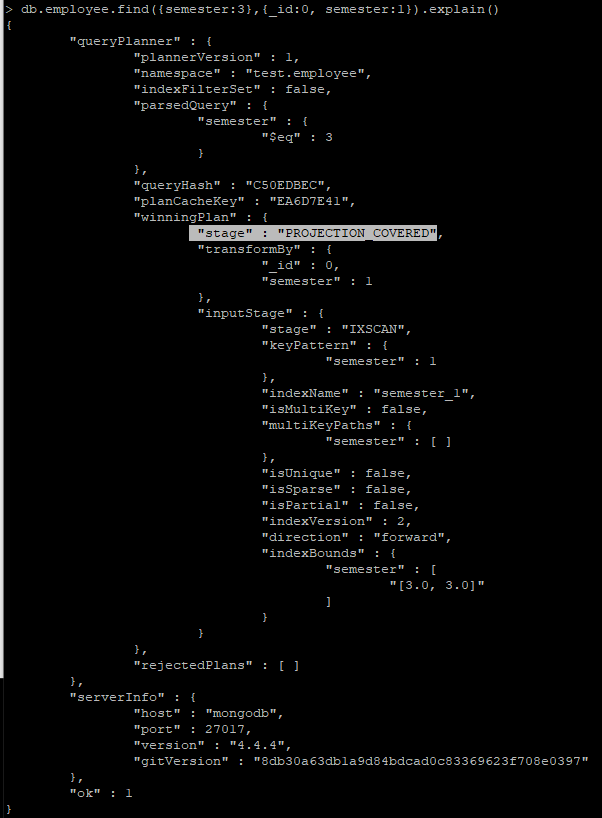
# 필드를 표시 안 하게 되는 경우 _id 필드가 표현 되기에 covered query가 되지 않음 (단순 인덱스 스캔 - fetch 진행)
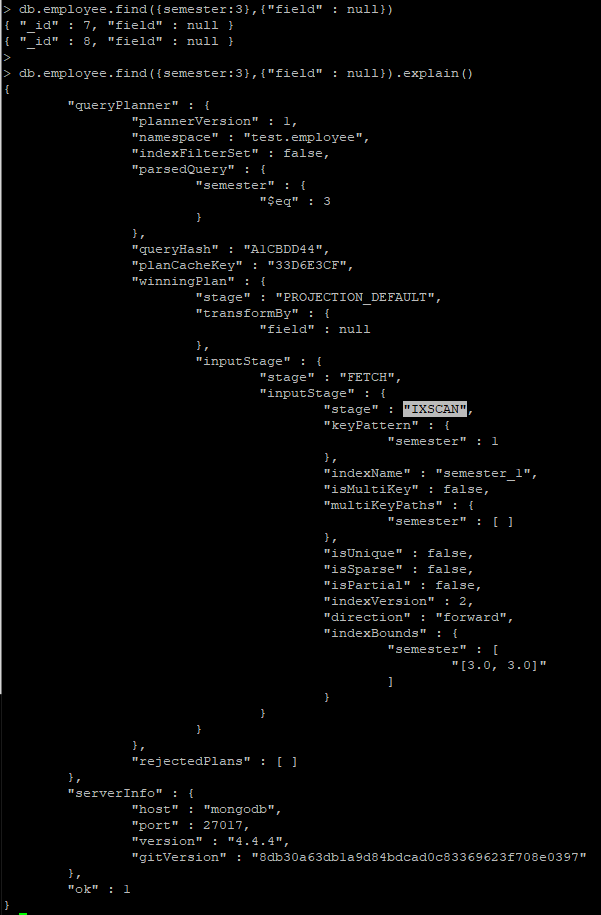
#실패 - embedded Document 에 대한 covered query 실패
> db.inventory.insertMany( [
{ item: "journal", instock: [ { warehouse: "A", qty: 5 }, { warehouse: "C", qty: 15 } ] },
{ item: "notebook", instock: [ { warehouse: "C", qty: 5 } ] },
{ item: "paper", instock: [ { warehouse: "A", qty: 60 }, { warehouse: "B", qty: 15 } ] },
{ item: "planner", instock: [ { warehouse: "A", qty: 40 }, { warehouse: "B", qty: 5 } ] },
{ item: "postcard", instock: [ { warehouse: "B", qty: 15 }, { warehouse: "C", qty: 35 } ] }
]);
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("603cf504850313ab26e27ced"),
ObjectId("603cf504850313ab26e27cee"),
ObjectId("603cf504850313ab26e27cef"),
ObjectId("603cf504850313ab26e27cf0"),
ObjectId("603cf504850313ab26e27cf1")
]
}
>
> db.inventory.createIndex({item:1, "instock.qty":1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
# 데이터 확인
> db.inventory.find({item:"journal", "instock.qty":5}, {_id:0,item:1, "instock.qty":1})
{ "item" : "journal", "instock" : [ { "qty" : 5 }, { "qty" : 15 } ] }
# covered 체크
> db.inventory.find({item:"journal", "instock.qty":5}, {_id:0,item:1, "instock.qty":1}).explain()
# 단일로 진행 실패
> db.inventory.insertOne({ item: "test_item", instock: [{warehouse: "A", qty: 5}]})
> db.inventory.find({item:"test_item", "instock.qty":5}, {_id:0,item:1, "instock.qty":1}).explain()
# 단일로 진행 실패 2
> db.inventory.insertOne({ item: "test_item_2", instock: [{qty: 5}]})
> db.inventory.find({item:"test_item_2", "instock.qty":5}, {_id:0,item:1, "instock.qty":1}).explain()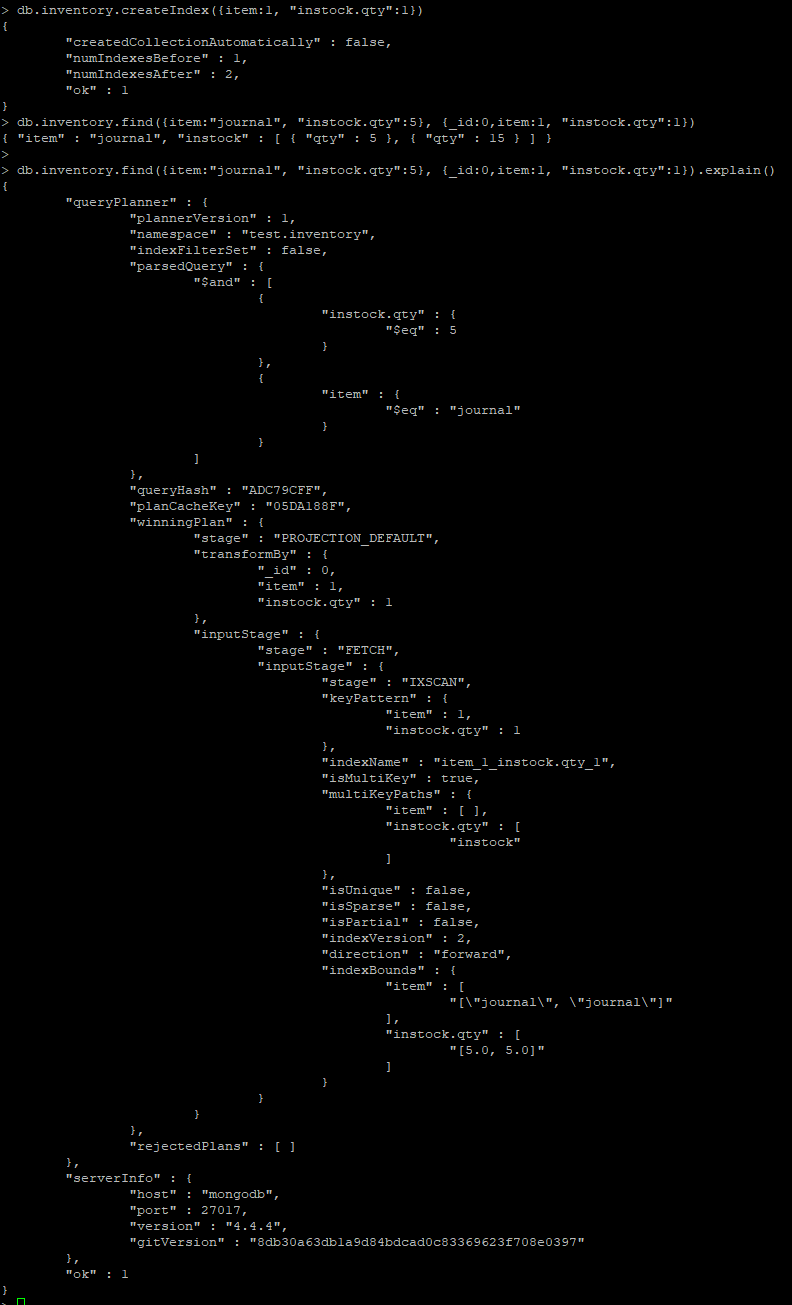
비교(Comparison) 연산자
|
operator |
설명 |
|
|
$eq |
(equals) 주어진 값과 일치하는 값 |
find({ 대상필드:{원하는연산자:조건값}})
|
|
$gt |
(greater than) 주어진 값보다 큰 값 |
|
|
$gte |
(greather than or equals) 주어진 값보다 크거나 같은 값 |
|
|
$lt |
(less than) 주어진 값보다 작은 값 |
|
|
$lte |
(less than or equals) 주어진 값보다 작거나 같은 값 |
|
|
$ne |
(not equal) 주어진 값과 일치하지 않는 값 |
|
|
$in |
주어진 배열 안에 속하는 값 |
반드시 배열 형태로 질의 find({필드:{$in / $nin :[ { 원하는값 A } , { 원하는값 B } ] } }) |
|
$nin |
주어진 배열 안에 속하지 않는 값 |
논리 연산자
|
operator |
설명 |
|
|
$or |
주어진 조건중 하나라도 true 일 때 true |
배열 형태로 질의 진행 find({$or / $and / $not / $nor : [{조건A},{조건B}]}) |
|
$and |
주어진 모든 조건이 true 일 때 true |
|
|
$not |
주어진 조건이 false 일 때 true |
|
|
$nor |
주어진 모든 조건이 false 일때 true |
> db.inventory.find({"instock.qty":{$eq:5}})
{ "_id" : ObjectId("603cf504850313ab26e27ced"), "item" : "journal", "instock" : [ { "warehouse" : "A", "qty" : 5 }, { "warehouse" : "C", "qty" : 15 } ] }
{ "_id" : ObjectId("603cf504850313ab26e27cee"), "item" : "notebook", "instock" : [ { "warehouse" : "C", "qty" : 5 } ] }
{ "_id" : ObjectId("603cf504850313ab26e27cf0"), "item" : "planner", "instock" : [ { "warehouse" : "A", "qty" : 40 }, { "warehouse" : "B", "qty" : 5 } ] }
{ "_id" : ObjectId("603cf675850313ab26e27cf2"), "item" : "test_item", "instock" : [ { "warehouse" : "A", "qty" : 5 } ] }
{ "_id" : ObjectId("603cf6d7850313ab26e27cf3"), "item" : "test_item_2", "instock" : [ { "qty" : 5 } ] }
# county 가 종로구,중구 또는 population 이 3,552,490 보다 큰 경우
> db.area.find({$or:[{county: "종로구"},{county:"중구"},{population:{$gte:3552490}}]})
{ "_id" : ObjectId("5c88f9f70da47a8507752775"), "city_or_province" : "서울", "county" : "종로구", "population" : 152737 }
{ "_id" : ObjectId("5c88f9f70da47a8507752776"), "city_or_province" : "서울", "county" : "중구", "population" : 125249 }
{ "_id" : ObjectId("5c88f9f70da47a850775278e"), "city_or_province" : "부산", "county" : "중구", "population" : 45208 }
{ "_id" : ObjectId("5c88f9f70da47a8507752830"), "city_or_province" : "대구", "county" : "중구", "population" : 79712 }
{ "_id" : ObjectId("5c88f9f70da47a850775283f"), "city_or_province" : "인천", "county" : "중구", "population" : 115249 }
{ "_id" : ObjectId("5c88f9f70da47a8507752848"), "city_or_province" : "대전", "county" : "중구", "population" : 252490 }
{ "_id" : ObjectId("5c88f9f70da47a850775284c"), "city_or_province" : "울산", "county" : "중구", "population" : 242536 }
# county 가 종로구,중구 가운데, population 이 125,249 보다 큰 경우 (and / or 연산이 공존)
> db.area.find({$and:[{$or:[{county: "종로구"},{county:"중구"}]},{population:{$gte:125249}}] })
{ "_id" : ObjectId("5c88f9f70da47a8507752775"), "city_or_province" : "서울", "county" : "종로구", "population" : 152737 }
{ "_id" : ObjectId("5c88f9f70da47a8507752776"), "city_or_province" : "서울", "county" : "중구", "population" : 125249 }
{ "_id" : ObjectId("5c88f9f70da47a8507752848"), "city_or_province" : "대전", "county" : "중구", "population" : 252490 }
{ "_id" : ObjectId("5c88f9f70da47a850775284c"), "city_or_province" : "울산", "county" : "중구", "population" : 242536 }
# county 가 종로구,중구 가운데, population 이 125,249 보다 큰 경우 ($and / $in 연산이 공존)
> db.area.find({$and:[{county:{$in:["종로구","중구"]}}, {population:{$gte:125249}}] })
{ "_id" : ObjectId("5c88f9f70da47a8507752775"), "city_or_province" : "서울", "county" : "종로구", "population" : 152737 }
{ "_id" : ObjectId("5c88f9f70da47a8507752776"), "city_or_province" : "서울", "county" : "중구", "population" : 125249 }
{ "_id" : ObjectId("5c88f9f70da47a8507752848"), "city_or_province" : "대전", "county" : "중구", "population" : 252490 }
{ "_id" : ObjectId("5c88f9f70da47a850775284c"), "city_or_province" : "울산", "county" : "중구", "population" : 242536 }$regex 연산자
- $regex 연산자(정규표현식)를 이용하여, Document를 찾을 수 있음
{ <field>: { $regex: /pattern/, $options: '<options>' } }
{ <field>: { $regex: 'pattern', $options: '<options>' } }
{ <field>: { $regex: /pattern/<options> } }
{ <field>: /pattern/<options> }- 4번쨰 라인 처럼 $regex 를 작성하지 않고 바로 정규식을 쓸 수도 있으며, $options 정보 를 이용도 가능
|
option |
설명 |
|
i |
대소문자 무시 |
|
m |
정규식에서 anchor(^) 를 사용 할 때 값에 \n 이 있다면 무력화 |
|
x |
정규식 안에있는 whitespace를 모두 무시 |
|
s |
dot (.) 사용 할 떄 \n 을 포함해서 매치 |
- 정규식 test_item_[1-2] 에 일치하는 값이 item 조회
- 조회하는 데이터의 "" 사용 안함.
> db.inventory.find({item : /test_item_[1-2]/})
{ "_id" : ObjectId("603cf6d7850313ab26e27cf3"), "item" : "test_item_2", "instock" : [ { "qty" : 5 } ] }
#대소문자 무시 i 옵션 이용
> db.inventory.find({item : /Test_item_[1-2]/i})
{ "_id" : ObjectId("603cf6d7850313ab26e27cf3"), "item" : "test_item_2", "instock" : [ { "qty" : 5 } ] }$text 연산자
- Text 검색으로 단어 형태만 검색이 가능 (띄어쓰기 단위 -> 가령 한 단어 내에 포함된 것은 검색이 안됨)
- 대 소문자 구분 안함
- 각 나라별 언어에 맞춰 검색이 지원되고 있지만, 한글은 지원되지 않음.
- 문자열 인덱스를 만들어야 사용 가능
- 해당 Collection 의 텍스트 인덱스 안에서만 작동하기 때문
|
필드 |
설명 |
|
$search |
검색하려는 내용을 담는다. 구절로 설정되지 않으면 띄어 쓴 단어를 포함한 모든 Document반환 |
|
$language |
Option. 검색하는 언어를 설정 MongoDB가 지원하는 언어를 설정할 수 있으며, 설정되지 않으면 인덱스에 설정된 내용을 따름 |
|
$caseSensitive |
Option. Bollean 값. 문자의 대,소문자 구분을 결정하며, Default는 구분하지 않음(False) |
|
$diacriticSensitive |
Option. Bollean 값. e`와 e 와 같이 알파벳의 위아래에 붙이는 기호를 무시할지를 정함. Default로는 false (무시 하지 않음) |
> db.inventory.createIndex({ item:"text" })
> db.inventory.find( {$text:{$search:"test"}} )
{ "_id" : ObjectId("603e498748883f8cbbc18bd9"), "item" : "keep Test" }
{ "_id" : ObjectId("603e47f148883f8cbbc18bd7"), "item" : "keep test" }
{ "_id" : ObjectId("603e47e248883f8cbbc18bd6"), "item" : "test keep" }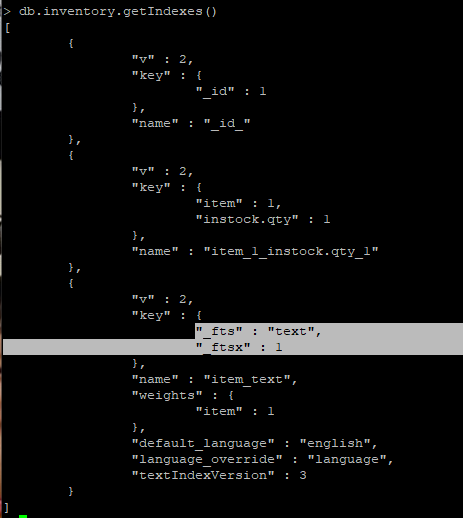
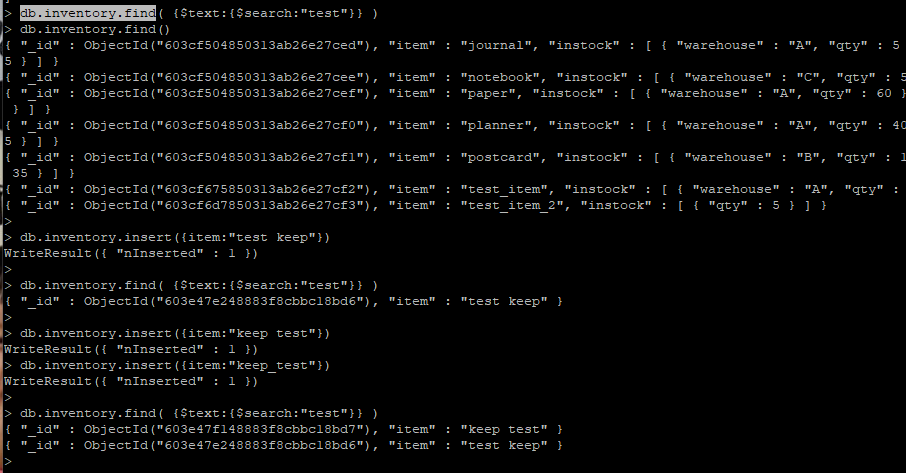
- 문자열 내 test 를 검색하는데, test_item 같은 것은 검색이 안됨. keep test / test keep 같이 띄어쓰기 된 것에 대해서만 검색
$where 연산자
- $where 연산자를 통하여 javascript expression 을 사용 가능
#comments field 가 비어있는 Document 조회
> db.articles.find( { $where: "this.comments.length == 0" } )
{ "_id" : ObjectId("56c0ab6c639be5292edab0c4"), "title" : "article01", "content" : "content01", "writer" : "Velopert", "likes" : 0, "comments" : [ ]
$elemMatch 연산자
- $elemMatch 연산자는 Embedded Documents 배열을 쿼리할때 사용
# comments 중 "Charlie" 가 작성한 덧글이 있는 Document 조회를 했을때, 게시물 제목과 Charlie의 덧글부분만 읽고싶은 경우
# 이렇게 해보면 의도와는 다르게 Delta 의 덧글도 출력
> db.articles.find(
{
"comments": {
$elemMatch: { "name": "Charlie" }
}
},
{
"title": true,
"comments.name": true,
"comments.message": true
}
)
{
"_id" : ObjectId("56c0ab6c639be5292edab0c6"),
"title" : "article03",
"comments" : [
{
"name" : "Charlie",
"message" : "Hey Man!"
},
{
"name" : "Delta",
"message" : "Hey Man!"
}
]
}
- Embedded Document 배열이 아니라 아래 Document의 "name" 처럼 한개의 Embedded Document 경우
> db.users.find({
"username": "velopert",
"name": { "first": "M.J.", "last": "K."},
"language": ["korean", "english", "chinese"]
}
)
> db.users.find({ "name.first": "M.J."})- Document의 배열이아니라 그냥 배열일 시에는 다음과 같이 Query
> db.users.find({ "language": "korean"})projection
- find() 메소드의 두번째 parameter 인 projection
- 쿼리의 결과값에서 보여질 field를 정할 대 사용
# article의 title과 content 만 조회
> db.articles.find( { } , { "_id": false, "title": true, "content": true } )
{ "title" : "article01", "content" : "content01" }
{ "title" : "article02", "content" : "content02" }
{ "title" : "article03", "content" : "content03" }$slice 연산자
- projector 연산자 중 $slice 연산자는 Embedded Document 배열을 읽을때 limit 설정
# title 값이 article03 인 Document 에서 덧글은 하나만 보이게 출력
$slice 가 없었더라면, 2개를 읽어와야하지만 1개로 제한을 두었기에 한개만 출력
> db.articles.find({"title": "article03"}, {comments: {$slice: 1}}).pretty()
{
"_id" : ObjectId("56c0ab6c639be5292edab0c6"),
"title" : "article03",
"content" : "content03",
"writer" : "Bravo",
"likes" : 40,
"comments" : [
{
"name" : "Charlie",
"message" : "Hey Man!"
}
]
}
$elemMatch
- 위의 elemMatch 는 조건 연산자에서 사용하는 것이며,
- 해당 elemMatch 는 필드 내, 즉 projection 파라메터 입니다.
# $elemMatch 연산자를 projection 연산자로 사용하면 이를 구현 가능
# comments 중 "Charlie" 가 작성한 덧글이 있는 Document 중 제목, 그리고 Charlie의 덧글만 조회 (필드 선언 시 다시 한번 더 eleMatch를 진행하게 되면 Delta 의 댓글은 안보임
> db.articles.find(
... {
... "comments": {
... $elemMatch: { "name": "Charlie" }
... }
... },
... {
... "title": true,
... "comments": {
... $elemMatch: { "name": "Charlie" }
... },
... "comments.name": true,
... "comments.message": true
... }
... )
{ "_id" : ObjectId("56c0ab6c639be5292edab0c6"), "title" : "article03", "comments" : [ { "name" : "Charlie", "message" : "Hey Man!" } ] }
[findAndModify]
- Single Document 에 대한 수정하고 반환
- 반환 된 Document는 수정에 대한 결과가 아님
- 반환 된 Document 에 수정한 내역을 확인하고 싶으면 new Option을 이용
- new 옵션을 true로 하는 경우 변경 후의 결과 값을 보여주며, Default 로 new 옵션을(false) 선언하지 않는 경우 변경 되기 전 값을 출력
# mosters 에서 name이 'Demon' 의 att를 350으로 변경하고 변경한 후 결과 확인
> db.monsters.findAndModify({ query: { name: 'Demon' }, update: { $set: { att: 350 } }, new: true })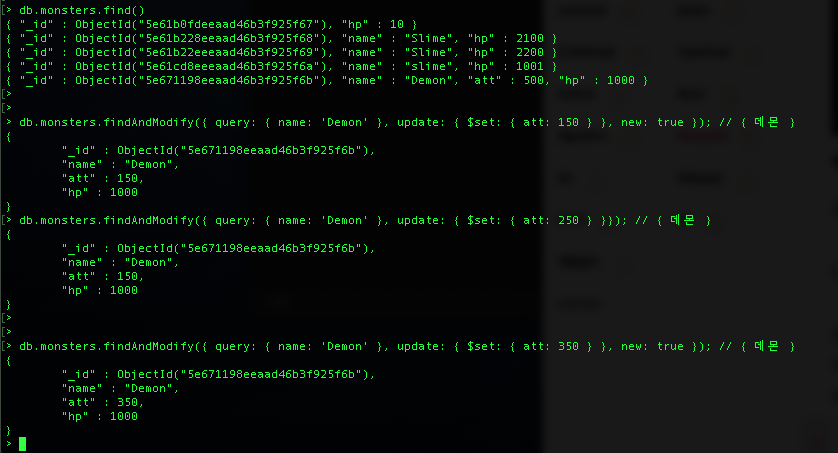
db.collection.findAndModify({
query: <document>,
sort: <document>,
remove: <boolean>,
update: <document or aggregation pipeline>, // Changed in MongoDB 4.2
new: <boolean>,
fields: <document>,
upsert: <boolean>,
bypassDocumentValidation: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ]
});
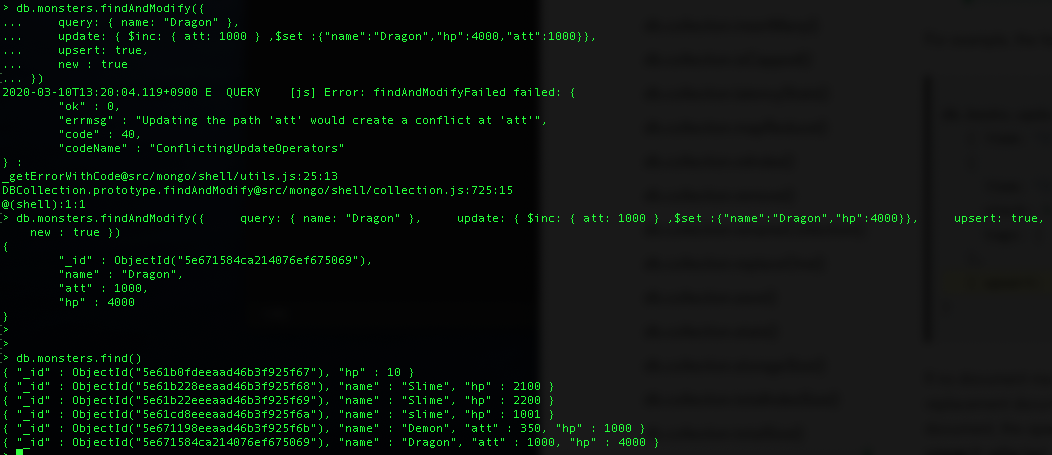
> db.monsters.findAndModify({
query: { name: "Dragon" },
update: { $inc: { "att": 1000 } ,$set :{"name":"Dragon","hp":4000,"att":1000}},
upsert: true,
new : true
})
> db.monsters.findAndModify({
query: { name: "Dragon" },
update: {$set :{"hp":2000,"att":2000}},
upsert: true,
new : true
})
> db.monsters.findAndModify({
query: { name: "Dragon" },
update: {$set :{"hp":3000,"att":2000}},
upsert: true
})
# upsert / new
> db.monsters.find( {query:{ name: "Dragon_Baby" }} )
> db.monsters.findAndModify({
query: { name: "Dragon_Baby" },
update: {$set :{"hp":1000,"att":500}},
upsert: true,
new : true
})
# remove
> db.monsters.findAndModify({
query: { name: "Dragon_Baby" },
remove: true
})
# 여러개일 경우
> db.monsters.findAndModify({
query: { name: "Dragon" },
update: {$set :{"hp":4000,"att":5000}},
upsert: true
})
- new Option : true

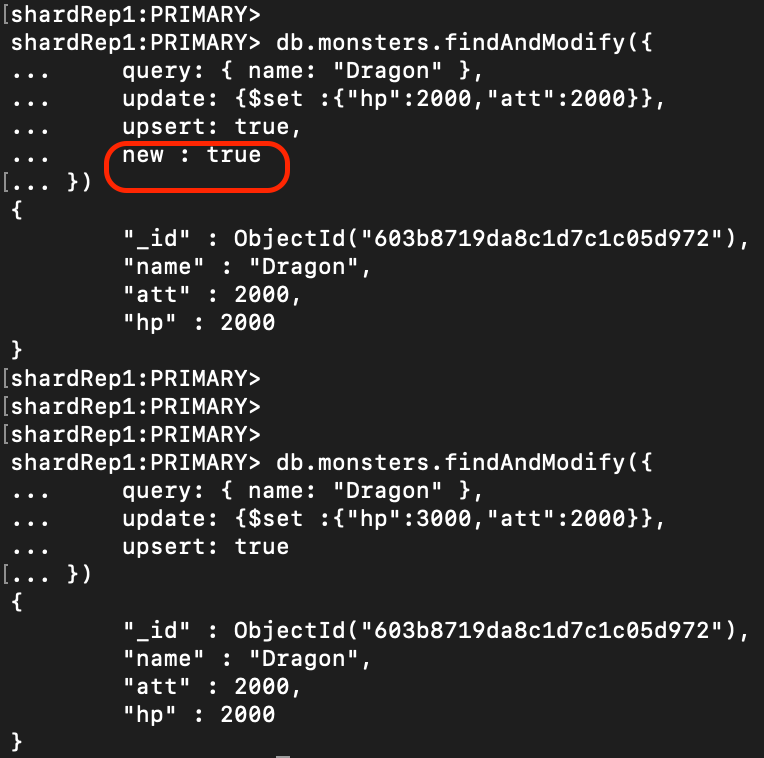
- upsert: true / new : true
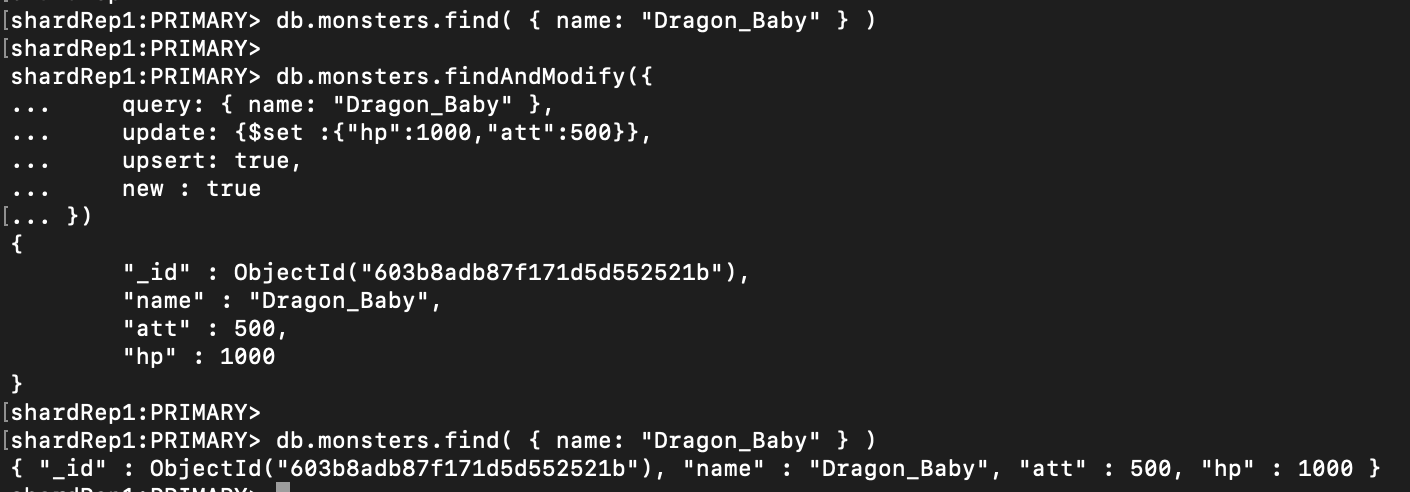
- remove : true
- new:true
- return 이 없기 때문에 에러
- update : {xxxx}
- 당연히 remove 되는데 update 에러 진행
- remove 가 정상적으로 진행 시
- 진행 이전 데이터 return 후 삭제
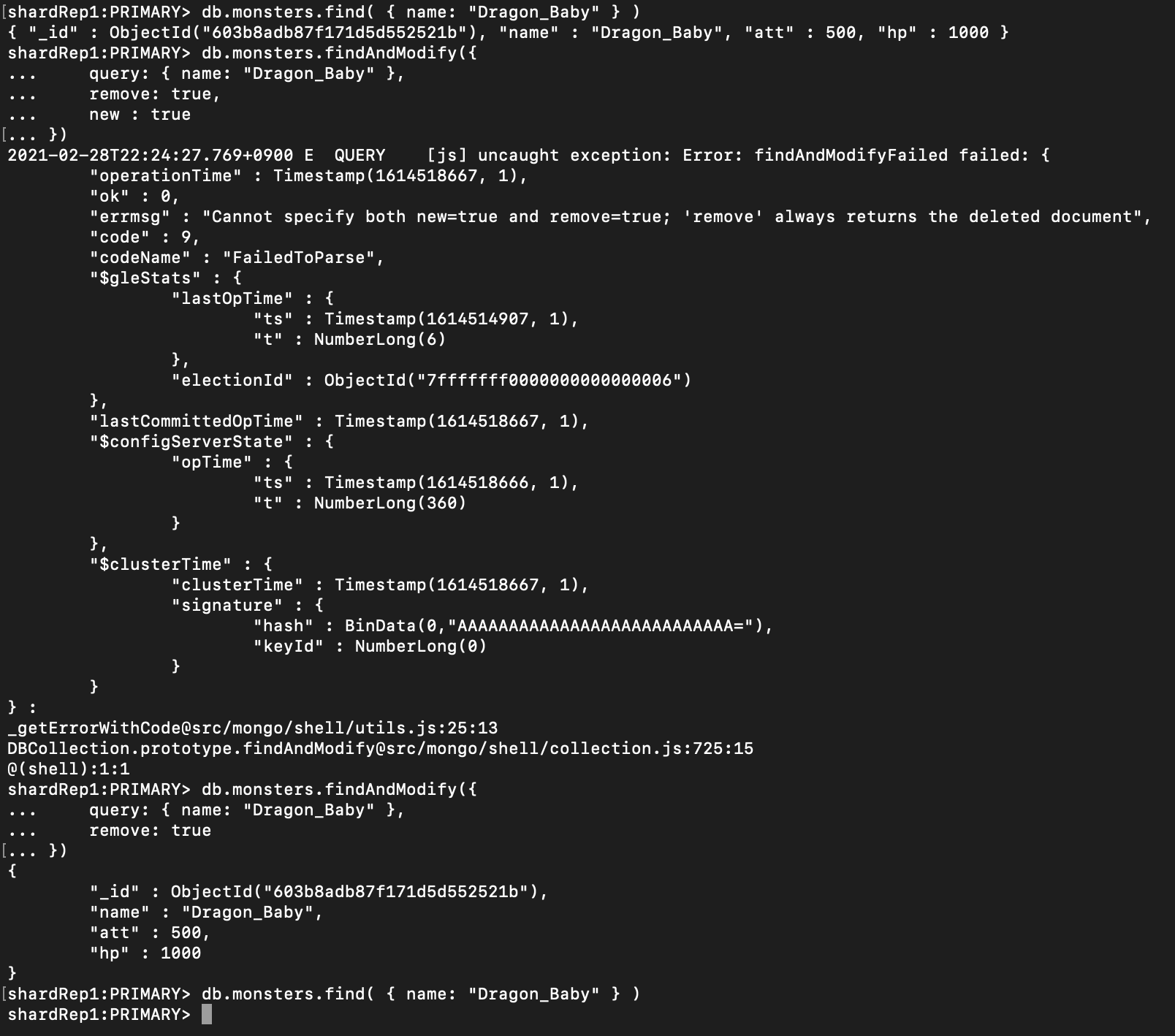
- 여러 개일 경우
- 역시 한 건만 변경 (update 처럼)
Cursor
- 지난 Mongodb Study-Break 때 제가 공유한 문서로 대체 합니다.
- hyunki1019.tistory.com/159
'MongoDB > MongoDB-Study_완료' 카테고리의 다른 글
| [MongoDB] [Study-9] Index (0) | 2021.04.16 |
|---|---|
| [MongoDB][Study-8] Aggregation (0) | 2021.04.16 |
| [MongoDB] [Study-6] MongoDB CRUD 쓰기 연산 (0) | 2021.03.28 |
| [MongoDB] [Study-Break] Cursor 간략한 정리 (0) | 2021.03.27 |
| [MongoDB][Study-4] MongoDB 기본 명령어 익히기 (0) | 2021.03.27 |