MongoDB의 Aggregate() 명령은 기본적으로 정렬을 위해서 100mb 메모리까지 사용 가능.
만약 그 이상의 데이터를 정렬해야 하는 경우라면 Aggregate() 명령은 실패-> 이 때 allowDiskUse 옵션을 true로 설정 시 Aggregate()처리가 디스크를 이용해 정렬 가능. 이 때 MongoDB 데이터 Directory 하의에 "_temp" Diretory 를 만들어 임시 가공용 데이터 파일을 저장
limit 와 batchSize 를 지정하지 않는 경우 batch는 한번 당 101개의 Document 결과를 리턴 하지만, Document 당 너무 많은 데이터가 있는 경우 batch 한번 당 1Mb 가 최대 size
limit 와 batchSize 를 지정하는 경우, 지정한 수만큼 리턴
큰 수로 셋팅하더라도 4Mb 이상의 데이터를 한번의 Batch로 가져올 수 없음.
인덱스 없이 데이터를 sort하는 경우 첫 번째 batch에 모든 데이터를 가져오지만, 최대 4 Mb 초과할 수 없음.
> // for문을 돌려서 간단한 데이터로 200개 document 를 등록한다.
> for (var i = 0; i < 200; i++) { db.foo.insert({i: i}); }
> var cursor = db.foo.find()
> // batchSize나 limit 값 지정없이 find 했으므로 기본 batch 크기인 101 documents
> cursor.objsLeftInBatch()
101
> // 한번에 모든 document들을 가져오기 위해 큰 limit 값을 셋팅하면 batchSize는 모든 document 수가 된다.
> var cursor = db.foo.find().limit(1000)
> cursor.objsLeftInBatch()
200
> // batchSize 가 limit 크기보다 작으면 batchSize가 우선한다.
> var cursor = db.foo.find().batchSize(10).limit(1000)
> cursor.objsLeftInBatch()
10
> // limit 가 batchSize 보다 작으면 limit 가 우선한다.
> var cursor = db.foo.find().batchSize(10).limit(5)
> cursor.objsLeftInBatch()
5
> // 각각 1MB 데이터로 10개의 document 를 등록한다.
> var megabyte = '';
> for (var i = 0; i < 1024 * 1024; i++) { megabyte += 'a'; }
> for (var i = 0; i < 10; i++) { db.bar.insert({s:megabyte}); }
> // limit나 batchSize를 지정하지 않았으므로 첫번째 batch는 1MB 에서 멈춘다.
> // 결국 1개씩 반복적으로 데이터를 가져오게됨
> var cursor = db.bar.find()
> cursor.objsLeftInBatch()
1
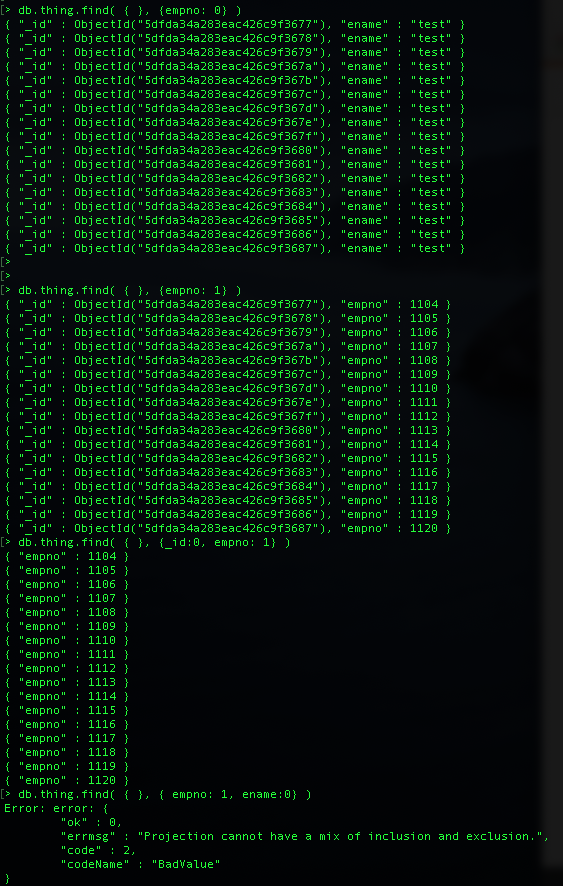
만약 empno만 빼고 다 보고자 하면 그때는 > db.thing.find( { }, {empno: 0} ) 이런식으로 표시
_id에 대해서만 혼용 사용 가능하며, 다른 필드들에 대해서는 1과 0을 혼용해서 표시 안됨
조건 검색 시 가급적 _id를 작성하며 Range 검색 시 기간을 지정하여 검색 추천
Ex) db.bios.find( {"_id":{"$gte":ObjectId("5dfaf5c00000000000000000", "$lte":ObjectId("5dfaf5c00000000000000000")}, {_id:0, name:1 , money:1}) (오늘 이전 모든 데이터 검색 or 오픈 이후 모든 날짜에 대해 검색 같은 전체 검색은 지양, 어제부터 일주일 전, 현재부터 하루 전 데이터 식으로 검색을 추천)
filed 명시 방법
> db.thing.find( { }, {empno: 1} )
// empno 를 표시하고, _id는 default로 표시, 단 그 외(ename) 은 표시 안함
> db.thing.find( { }, {empno: 0} )
// empno 만 표시를 안하고 나머지 ename , _id는 표시
> db.thing.find( { }, {_id:0, empno: 1} )
// empno만 표시하고, _id 및 다른 필드는 표시 안함.
// 여기서 중요한건 _id는 항상 명시해 줘야 하며, 보고 싶은 필드만 1로 설정해서 표시
// 다른 필드의 경우 ename이 있더라도 ename:0 으로 하면 에러 발생 >> 왜?????
> db.thing.find( { }, {empno: 1, ename:0} )
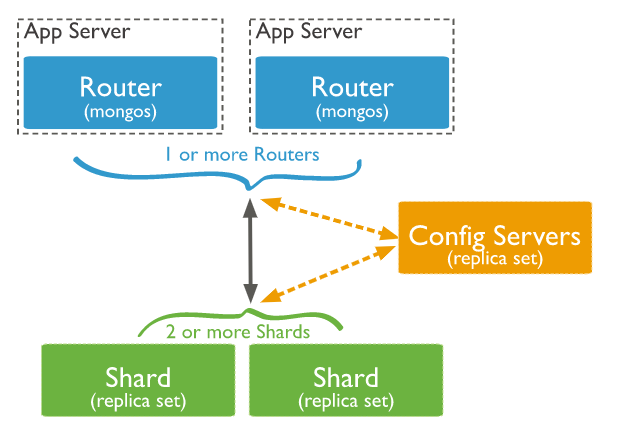
MongoS가 데이터를 쓰고/읽기 작업을 수행할 때 Config 서버는 MongoS를 통해 데이터를 동기화-수집 진행
MongoS
데이터를 Shard 서버로 분배해 주는 프로세스 (Router-Balancer)
Data를 분산하다 보면 작업의 일관성을 위하여 Lock을 사용
이때 Chunk Size를 적절하게 설계하지 못하면 Migration 때문에 성능 저하 현상이 발생 가능성
DB 사용량이 적은 시간대 Balancer를 동작시키고 그 외 시간에는 끄는 방법도 성능 향상의 방법
하나 이상의 프로세스가 활성화 가능(여러대의 MongoS를 운영 가능)
Application Server에서 실행 가능 (Application에서 직접적으로 접속하는 주체이며,독립적인 서버로 동작 가능하며, Application 서버 내에서도 API 형태로 실행 가능)
MongoS를 Application Server 서버 local 에 설치하는 것을 추천 (application server 가 별도의 라우터를 네트워크 공유 안하고, Local에서 직접 접근하기 때문에 효율성 증가. 별도의 서버를 구축 하지 않아서 서버 비용 절감. 단, 관리 포인트로 인한 문제점도 존재)
> ObjectId("507c7f79bcf86cd7994f6c0e").getTimestamp()
ISODate("2012-10-15T21:26:17Z")
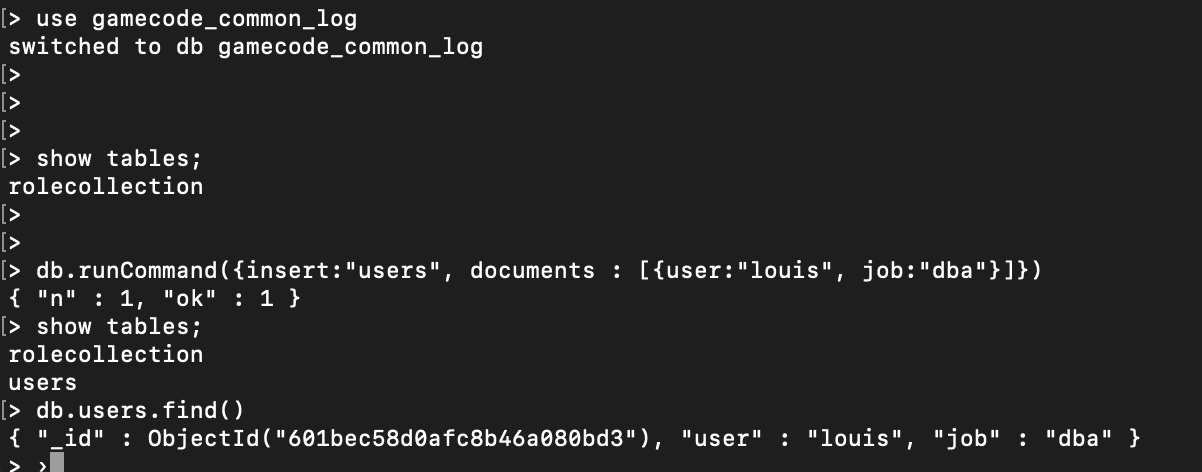
use database1 // database 선택
db.collection1.insert({ // collection.명령어 document
"name" : "Rouis.Kim" // field : value
, "age" : 37 // field : integer value
, "role" : "DBA" // field : string value
, "exp" : [{"Dev" : 5, "DBA" : 6}, {"Game": 3, "Ecommercail":2, "Enginner":3,"etc":3}] // field : Object value
, "loc" : [37.504997827623406, 127.02381255144938] // field : geomentry
, "etc" : ["2 daughters","프로이직러"] // field : array value
})
// document가 생성되지만, collection 이 존재하지 않으면 collection, database가 존재 하지않으면 database 까지 생성 됨
// schemaless (스키마 유연성)