안녕하세요.
RDS Slow query 를 수집하기 위해서 알아보던 도중(예전에 김종열 팀장님 도움으로 python으로 수집하던 소스는 있지만, UI로 보여주고 싶은 마음에) ELK 를 이용하면 제가 원하는 화면을 보여줄 수 있을 것 같아서 시작하게 되었습니다.
EC2에 ELK를 설치 후 Filebeat 를 이용하면 가능했지만, 아래와 같은 문제점이 있었습니다.
1. Slowquery를 다운 받아 진행하게 된다면, 실시간이 아닌 배치 형태로 진행이라 실시간으로 보기 원하는 부분에 대해 니즈에 부합
2. ELK 에 대해 유지보수 필요
3. 다운 받은 Slowquery 에 대해 관리 필요
등으로 인해 AWS ELK를 찾아보게 되었습니다.
다행히 AWS ELK는 정말 만들기 쉽더군요. (ec2에서 ELK도 어렵운건 아니지만..)
이후 아래 영상을 통해 cloudwatch상에 올라가 있는 slowquery를 ELK로 연동하는 것도 쉽게 할 수 있었습니다.
www.slideshare.net
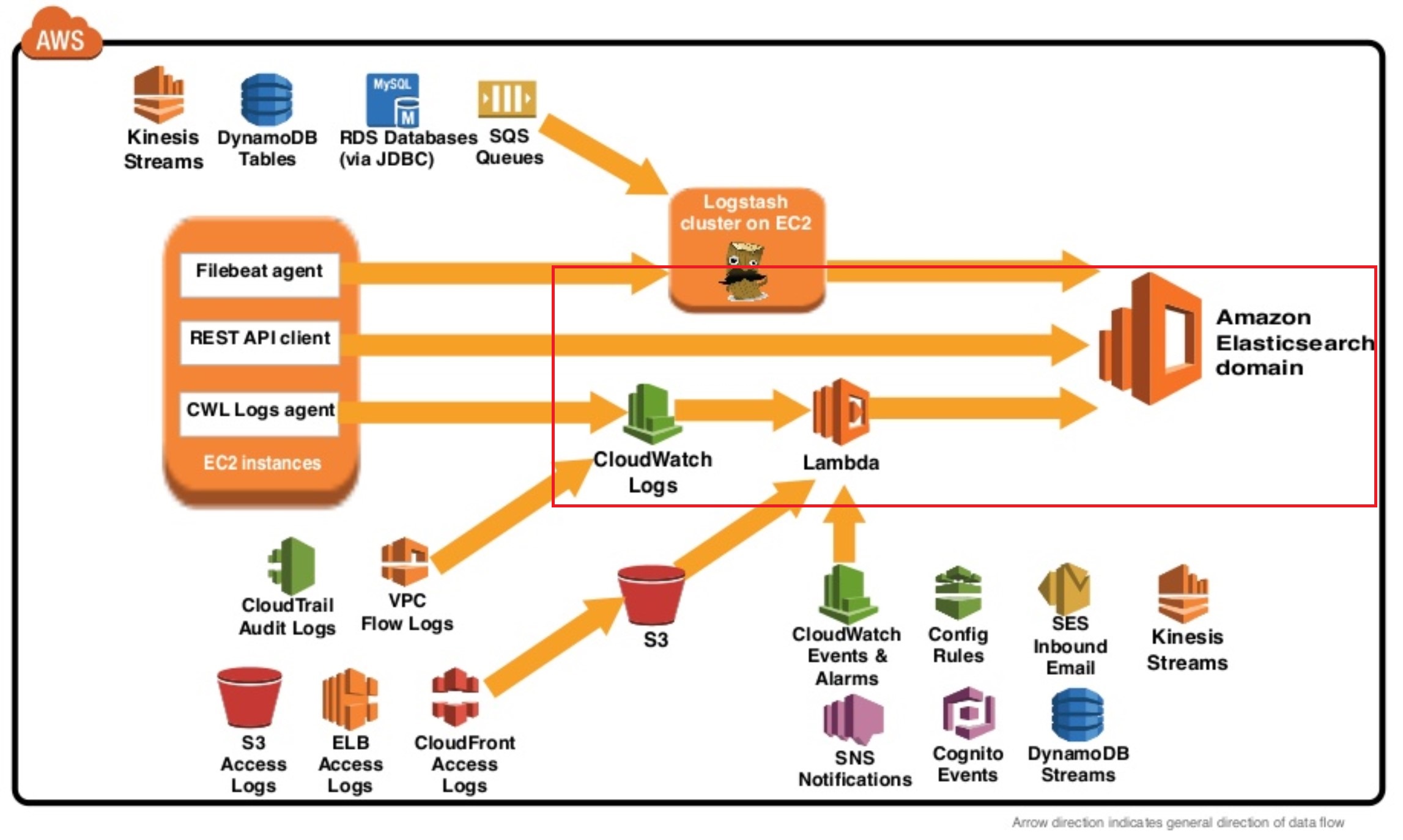
위의 연동을 간단하게 이미지로 정리하면 아래와 같습니다.
빨간색 네모로 표신한 정도가 됩니다.
RDS Slow query 발생 -> Cloudwatch Log -> Lambda(AWS제공) -> Elasticsearch Service(ES) -> Kibana
이제 아래는 Cloudwatch Slow log를 ELK 로 연동하는 설정 부분입니다.
1. Cloudwatch 의 로그 목록 선택 후 (slow query 선택 후 Elasticsearch Service 측 스트림 선택)
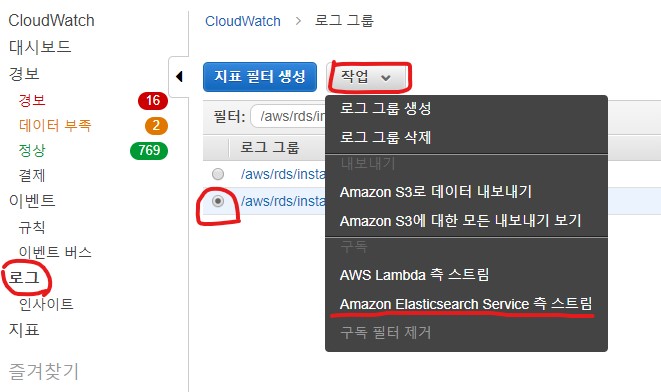
2. 생성한 ES 선택(Elasticsearch Service)

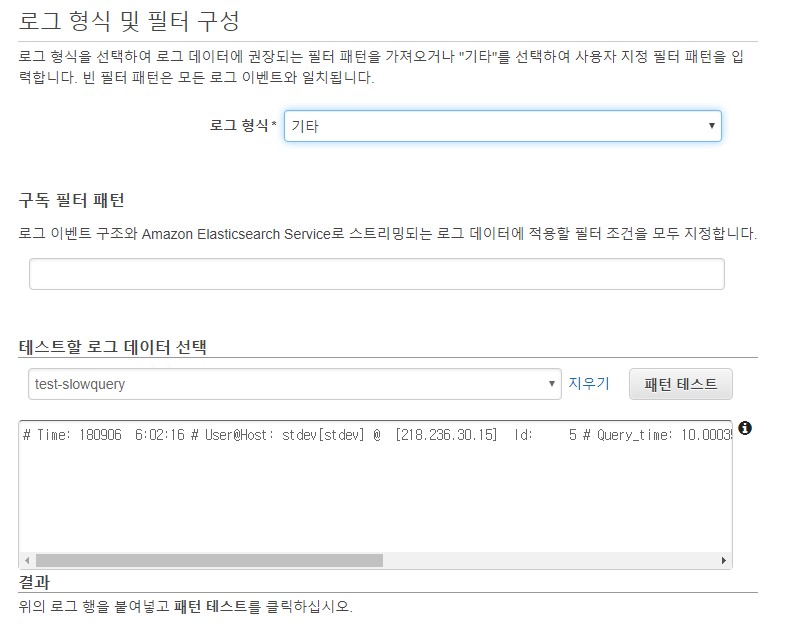
3. 로그 형식 및 필터 구성 시 기타로 설정
기타로 선택하는 이유는 여기서 필터패턴을 하게 되면 Slowquery의 여러 형태로 인해 원치 않은 데이터가 다른 형태로 필터가 되는 현상 발생
또한, cloudwatch 로그 형식 필터에서 아직까지 정규화 표현식을 제공하지 않으므로 slowquery를 필터 적용하기에는 맞지 않음(띄어쓰기 필터 등만 지원)
4. 이후 별다른 설정 없이 진행(스트리밍 시작)


- 구독되고 있는 것을 확인 가능(여기서 중요한 것은 모든 cloudwatch 를 이용해서 ES 로 보내는 작업-비단 Slowquery 뿐만 아니라 모든 작업/ 은 동일한 Lambda호출/ 2번의 캡쳐 화면을 보면 Lambda함수에 대한 내용이 있음)


하지만 Cloudwatch에서 제공하는 필터는 RDS slowquery 형태에 맞지 않습니다. 더군다나 쿼리들마다 형태가 다르다 보니 정영화 되지 않은 데이터를 일괄적인 형태로 보여지는 것에 대해서는 한계가 있더군요.
더불어 여러 RDS에서 들어오는 slowquery를 AWS에서 제공하는 하나의 lambda(node.js) 에서만 처리가 되니 어느 DB에서 생긴 slowquery인지 확인이 어렵더군요.
다행히, AWS Support 에 문의 하였더니 Lambda 수정의 방법과 기존 고려했던 export 받은 후 처리 2가지 방법을 제시하였으며, Lambda의 경우 친절하게 수정한 코더도 주시더군요!!!
하지만, Lambda 수정은 제 몫이기에 처음으로 접해보는 node.js를 잡고 끙끙대기 시작했습니다.
console.log 를 이용한 일일이 로그 찍어가며 테스트하며 수정을 했습니다.
아래는 수정한 Lambda입니다. 개발자 분들이 보시면 얼마나 욕할지...ㅠㅠ하지만 저는 개발자가 아니기에...당당히 소스를 공유 합니다.
수정하셔도 되고 그대로 적용하셔도 됩니다.(무슨 근자감...)
수정 부분은 2군데 입니다.
1. 여기는 rds의 네임을 cwl 뒤에 작성해 줌으로서 구분이 가능해 집니다.(AWS Jihyun B. 님이 제공)
// index name format: cwl-YYYY.MM.DD Slowquery modify 1
/*
var indexName = [
'cwl-' + timestamp.getUTCFullYear(), // year
('0' + (timestamp.getUTCMonth() + 1)).slice(-2), // month
('0' + timestamp.getUTCDate()).slice(-2) // day
].join('.');
*/
var indexName = [
'cwl' + payload.logGroup.toLowerCase().split('/').join('-') + '-' + timestamp.getUTCFullYear(), // log group + year
('0' + (timestamp.getUTCMonth() + 1)).slice(-2), // month
('0' + timestamp.getUTCDate()).slice(-2) // day
].join('.');2. 여기는 정규표현식을 이용하여 slow query 를 파싱 및 필터를 적용한 후 맵핑하는 곳입니다. 참고로 저는 node.js 는 처음이며, 정규표현식도 모릅니다..ㅠ그래서 하드 코딩을 했는데...동적으로 코딩 하기에는 머리가 안돌아가서 그냥 포기했습니다. 이쁘게 사용하실 분은 수정하셔도 됩니다.
message는 slow 쿼리의 전문이 들어오는 곳이며, extractedFields 는 맵핑하는 형태가 들어오는 곳인데, 우리가 필터를 기타로 한 후 작성안하고 넘기기 때문에 if 문에 걸리지 않고 else 로 빠지는 것입니다.
function buildSource(message, extractedFields) {
...
if 문 끝에 else로 추가
...
//Slowquery add
else {
console.log('Slow query Regular expression')
var qualityRegex = /User@Host: ([^&@]+) /igm;
var ipRegex = /\d+\.\d+\.\d+\.\d+/igm;
var querytimeReg = /Query_time: ([^& ]+)/igm;
var locktimeReg = /Lock_time: ([^& ]+)/igm;
var querytimeReg = /Query_time: ([^& ]+)/igm;
var rowsentReg = /Rows_sent: ([\d^&]+)/igm;
var rowexaminedReg = /Rows_examined: ([\d^&]+)/igm;
var slowqueryReg = /select ([^&;]+)|update ([^&;]+)|delete ([^&;]+)/igm;
var userhost, ip, querytime, querylock, rowsent, rowexaminge, slowquery ='';
var matches, qualities = [];
var source = {};
while (matches = qualityRegex.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
userhost = qualities[0];
ip = ipRegex.exec(message)[0];
matches, qualities = [];
while (matches = querytimeReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
querytime = qualities[0];
matches, qualities = [];
while (matches = locktimeReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
querylock = qualities[0];
matches, qualities = [];
while (matches = rowsentReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
rowsent = qualities[0];
matches, qualities = [];
while (matches = rowexaminedReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
rowexamined = qualities[0];
slowquery = slowqueryReg.exec(message)[0];
console.log(userhost);
console.log(ip);
console.log(querytime);
console.log(querylock);
console.log(rowsent);
console.log('hyungi rowexaminge: ',rowexamined);
console.log('hyungi query :',slowquery);
source['User@Host'] = userhost;
source['IP'] = ip;
source['Query_time'] = 1 * querytime;
source['Lock_time'] = 1 * querylock;
source['Rows_sent'] = 1 * rowsent;
source['Rows_examined'] = 1 * rowexamined;
source['Query'] = slowquery;
console.log('Slow query Filter complete : ', source)
return source;
}
아래는 전체 Lambda 소스 입니다.( LogsToElasticsearch_st-elk-slowquery )
// v1.1.2
var https = require('https');
var zlib = require('zlib');
var crypto = require('crypto');
var endpoint = 'search-st-elk-slowquery-edn6wa74e2h3zchmep6lbu2xky.ap-northeast-2.es.amazonaws.com';
// Set this to true if you want to debug why data isn't making it to
// your Elasticsearch cluster. This will enable logging of failed items
// to CloudWatch Logs.
var logFailedResponses = false;
exports.handler = function(input, context) {
// decode input from base64
var zippedInput = new Buffer.from(input.awslogs.data, 'base64');
// decompress the input
zlib.gunzip(zippedInput, function(error, buffer) {
if (error) { context.fail(error); return; }
// parse the input from JSON
var awslogsData = JSON.parse(buffer.toString('utf8'));
// transform the input to Elasticsearch documents
var elasticsearchBulkData = transform(awslogsData);
// skip control messages
if (!elasticsearchBulkData) {
console.log('Received a control message');
context.succeed('Control message handled successfully');
return;
}
// post documents to the Amazon Elasticsearch Service
post(elasticsearchBulkData, function(error, success, statusCode, failedItems) {
console.log('Response: ' + JSON.stringify({
"statusCode": statusCode
}));
if (error) {
logFailure(error, failedItems);
context.fail(JSON.stringify(error));
} else {
console.log('Success: ' + JSON.stringify(success));
context.succeed('Success');
}
});
});
};
function transform(payload) {
if (payload.messageType === 'CONTROL_MESSAGE') {
return null;
}
var bulkRequestBody = '';
payload.logEvents.forEach(function(logEvent) {
var timestamp = new Date(1 * logEvent.timestamp);
// index name format: cwl-YYYY.MM.DD Slowquery modify 1
/*
var indexName = [
'cwl-' + timestamp.getUTCFullYear(), // year
('0' + (timestamp.getUTCMonth() + 1)).slice(-2), // month
('0' + timestamp.getUTCDate()).slice(-2) // day
].join('.');
*/
var indexName = [
'cwl' + payload.logGroup.toLowerCase().split('/').join('-') + '-' + timestamp.getUTCFullYear(), // log group + year
('0' + (timestamp.getUTCMonth() + 1)).slice(-2), // month
('0' + timestamp.getUTCDate()).slice(-2) // day
].join('.');
var source = buildSource(logEvent.message, logEvent.extractedFields);
source['@id'] = logEvent.id;
source['@timestamp'] = new Date(1 * logEvent.timestamp).toISOString();
source['@message'] = logEvent.message;
source['@owner'] = payload.owner;
source['@log_group'] = payload.logGroup;
source['@log_stream'] = payload.logStream;
var action = { "index": {} };
action.index._index = indexName;
action.index._type = payload.logGroup;
action.index._id = logEvent.id;
bulkRequestBody += [
JSON.stringify(action),
JSON.stringify(source),
].join('\n') + '\n';
});
return bulkRequestBody;
}
function buildSource(message, extractedFields) {
if (extractedFields) {
var source = {};
for (var key in extractedFields) {
if (extractedFields.hasOwnProperty(key) && extractedFields[key]) {
var value = extractedFields[key];
if (isNumeric(value)) {
source[key] = 1 * value;
continue;
}
jsonSubString = extractJson(value);
if (jsonSubString !== null) {
source['$' + key] = JSON.parse(jsonSubString);
}
source[key] = value;
}
}
return source;
}
//Slowquery add
else {
console.log('Slow query Regular expression')
var qualityRegex = /User@Host: ([^&@]+) /igm;
var ipRegex = /\d+\.\d+\.\d+\.\d+/igm;
var querytimeReg = /Query_time: ([^& ]+)/igm;
var locktimeReg = /Lock_time: ([^& ]+)/igm;
var querytimeReg = /Query_time: ([^& ]+)/igm;
var rowsentReg = /Rows_sent: ([\d^&]+)/igm;
var rowexaminedReg = /Rows_examined: ([\d^&]+)/igm;
var slowqueryReg = /select ([^&;]+)|update ([^&;]+)|delete ([^&;]+)/igm;
var userhost, ip, querytime, querylock, rowsent, rowexaminge, slowquery ='';
var matches, qualities = [];
var source = {};
while (matches = qualityRegex.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
userhost = qualities[0];
ip = ipRegex.exec(message)[0];
matches, qualities = [];
while (matches = querytimeReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
querytime = qualities[0];
matches, qualities = [];
while (matches = locktimeReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
querylock = qualities[0];
matches, qualities = [];
while (matches = rowsentReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
rowsent = qualities[0];
matches, qualities = [];
while (matches = rowexaminedReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
rowexamined = qualities[0];
slowquery = slowqueryReg.exec(message)[0];
console.log(userhost);
console.log(ip);
console.log(querytime);
console.log(querylock);
console.log(rowsent);
console.log('hyungi rowexaminge: ',rowexamined);
console.log('hyungi query :',slowquery);
source['User@Host'] = userhost;
source['IP'] = ip;
source['Query_time'] = 1 * querytime;
source['Lock_time'] = 1 * querylock;
source['Rows_sent'] = 1 * rowsent;
source['Rows_examined'] = 1 * rowexamined;
source['Query'] = slowquery;
console.log('Slow query Filter complete : ', source)
return source;
}
jsonSubString = extractJson(message);
if (jsonSubString !== null) {
return JSON.parse(jsonSubString);
}
return {};
}
function extractJson(message) {
var jsonStart = message.indexOf('{');
if (jsonStart < 0) return null;
var jsonSubString = message.substring(jsonStart);
return isValidJson(jsonSubString) ? jsonSubString : null;
}
function isValidJson(message) {
try {
JSON.parse(message);
} catch (e) { return false; }
return true;
}
function isNumeric(n) {
return !isNaN(parseFloat(n)) && isFinite(n);
}
function post(body, callback) {
var requestParams = buildRequest(endpoint, body);
var request = https.request(requestParams, function(response) {
var responseBody = '';
response.on('data', function(chunk) {
responseBody += chunk;
});
response.on('end', function() {
var info = JSON.parse(responseBody);
var failedItems;
var success;
var error;
if (response.statusCode >= 200 && response.statusCode < 299) {
failedItems = info.items.filter(function(x) {
return x.index.status >= 300;
});
success = {
"attemptedItems": info.items.length,
"successfulItems": info.items.length - failedItems.length,
"failedItems": failedItems.length
};
}
if (response.statusCode !== 200 || info.errors === true) {
// prevents logging of failed entries, but allows logging
// of other errors such as access restrictions
delete info.items;
error = {
statusCode: response.statusCode,
responseBody: info
};
}
callback(error, success, response.statusCode, failedItems);
});
}).on('error', function(e) {
callback(e);
});
request.end(requestParams.body);
}
function buildRequest(endpoint, body) {
var endpointParts = endpoint.match(/^([^\.]+)\.?([^\.]*)\.?([^\.]*)\.amazonaws\.com$/);
var region = endpointParts[2];
var service = endpointParts[3];
var datetime = (new Date()).toISOString().replace(/[:\-]|\.\d{3}/g, '');
var date = datetime.substr(0, 8);
var kDate = hmac('AWS4' + process.env.AWS_SECRET_ACCESS_KEY, date);
var kRegion = hmac(kDate, region);
var kService = hmac(kRegion, service);
var kSigning = hmac(kService, 'aws4_request');
var request = {
host: endpoint,
method: 'POST',
path: '/_bulk',
body: body,
headers: {
'Content-Type': 'application/json',
'Host': endpoint,
'Content-Length': Buffer.byteLength(body),
'X-Amz-Security-Token': process.env.AWS_SESSION_TOKEN,
'X-Amz-Date': datetime
}
};
var canonicalHeaders = Object.keys(request.headers)
.sort(function(a, b) { return a.toLowerCase() < b.toLowerCase() ? -1 : 1; })
.map(function(k) { return k.toLowerCase() + ':' + request.headers[k]; })
.join('\n');
var signedHeaders = Object.keys(request.headers)
.map(function(k) { return k.toLowerCase(); })
.sort()
.join(';');
var canonicalString = [
request.method,
request.path, '',
canonicalHeaders, '',
signedHeaders,
hash(request.body, 'hex'),
].join('\n');
var credentialString = [ date, region, service, 'aws4_request' ].join('/');
var stringToSign = [
'AWS4-HMAC-SHA256',
datetime,
credentialString,
hash(canonicalString, 'hex')
] .join('\n');
request.headers.Authorization = [
'AWS4-HMAC-SHA256 Credential=' + process.env.AWS_ACCESS_KEY_ID + '/' + credentialString,
'SignedHeaders=' + signedHeaders,
'Signature=' + hmac(kSigning, stringToSign, 'hex')
].join(', ');
return request;
}
function hmac(key, str, encoding) {
return crypto.createHmac('sha256', key).update(str, 'utf8').digest(encoding);
}
function hash(str, encoding) {
return crypto.createHash('sha256').update(str, 'utf8').digest(encoding);
}
function logFailure(error, failedItems) {
if (logFailedResponses) {
console.log('Error: ' + JSON.stringify(error, null, 2));
if (failedItems && failedItems.length > 0) {
console.log("Failed Items: " +
JSON.stringify(failedItems, null, 2));
}
}
}
이렇게 하면 Elastisearch 에서 index 가 생성 되었는지 체크하면 됩니다.
- Slowquery 가 발생해야 생성이 되므로 Lamdba 까지 수정이 완료 되었다면 제대로 들어 오는지 체크를 위해 DB에서 select sleep(30); 으로 슬로우 쿼리 생성 진행
- Lamdba 가 호출 되어서 진행 되었는지 Cloudwatch 통해서 확인 가능(수정한 Lamdba 로그가 생성 되었는지 체크도 가능
이렇게 하여 RDS 모든 서비스에 대해 Slow쿼리를 Kibana통해서 확인이 되네요.
뿌듯하네요! 이제 Slowquery 모니터링 합시다.
참고
- node.js 정규화표현식
https://developer.mozilla.org/ko/docs/Web/JavaScript/Guide/%EC%A0%95%EA%B7%9C%EC%8B%9D
정규 표현식
정규 표현식은 문자열에 나타는 특정 문자 조합과 대응시키기 위해 사용되는 패턴입니다. 자바스크립트에서, 정규 표현식 또한 객체입니다. 이 패턴들은 RegExp의 exec 메소드와 test 메소드 ,그리고 String의 match메소드 , replace메소드 , search메소드 , split 메소드와 함께 쓰입니다 . 이 장에서는 자바스크립트의 정규식에 대하여 설명합니다.
developer.mozilla.org
- node.js 를 직접 코딩하여 정규표현식 통해서 확인이 가능한지 간단하게 테스트 할 수 있습니다.
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp
developer.mozilla.org
- node.js 정규표현식
https://stackoverflow.com/questions/7954022/javascript-regular-expression-multiple-match
Javascript Regular Expression multiple match
I'm trying to use javascript to do a regular expression on a url (window.location.href) that has query string parameters and cannot figure out how to do it. In my case, there is a query string para...
stackoverflow.com
- 정규표현식 테스트
https://regexr.com/
RegExr: Learn, Build, & Test RegEx
RegExr is an online tool to learn, build, & test Regular Expressions (RegEx / RegExp).
regexr.com




