메모리 DB (높은 처리량 - Replication 읽기 및 쓰기, 대기 시간 등 높은 처리 가능)
레디스와 호환이 되며, 레디스 관련한 것들을 모두 사용 가능 (v6.2)
Multi-AZ 를 지원하여 빠르게 failover 및 복구, 재시작이 가능
특징
Primary / Replica 간의 강력한 일관성 보장
ms 단위의 읽기,쓰기 지연시간 (클러스터당 최대 1억6천만 tps)
redis 호환
빠른 데이터 복구 및 재시작 제공 (multi-az, transaction log )
multi-az를 통한 자동 페일오버 및 노드 fail에 대한 감지 및 복구
replication 및 shard를 이용한 노드 추가, scale out, scale up-down 가능
primary 에 대한 read/write 일관성 보장 및 복제 노드에 대한 일관성 보장 가능(read / write concern으로 예상)
사용자 인증 및 네트워크 인증, 암호화 기능 제공
s3로 자동 스냅샷 (최대 35일 - rds 와 동일)
하나의 클러스터로 최대 500개 노드 및 100tb 이상의 storage 지원(레플리카 포함)
AWS KMS keys를 사용한 TLS 암호화(8번과 동일)
Redis를 통한 사용자 인증 및 권한 부여(ACL)(8번과 동일)
AWS Graviton2 인스턴스 유형 지원
VPC, Cloudwatch, CloudTrail, AWS SNS 서비스와의 통합
완전 관리형 소프트웨어 패치 및 업그레이드 지원
관리 API를 위한 AWS IAM(Identity and Access Management) 통합 및 태그 기반 액세스 제어
주요 기능
Cluster
MemoryDB 서비스를 운영하는 하나 이상의 노드 모음 (서비스의 개념)
Shard는 Memory DB Set 단위들의 모임으로 Cluster 내에 존재
Noes ⊂ Shard ⊂ Cluster = 서비스 DB
Memory DB Set 에는 하나의 Primary 와 최대 5개의 Replica 노드들을 보유 가능
Primary 는 read/write 가능하며, Replica node들은 only read 만 처리
Primary 장애 시 replica node들 중 하나를 primary 로 승격
cluster 생성 시 redis 버전을 지정
cluster 내 Memory DB 기능
cluster 추가
cluster 수정
cluster 스냅샷 가져오기
cluster 삭제
cluster 내 요소 보기
cluster 에 비용 할당 태그 추가 / 삭제
Nodes
MemoryDB 구성 중 가장 작은 단위 (EC2 기반)
클러스터에 속하며, cluster 생성 시 정해진 버전의 엔진 기반
필요한 경우 클러스터의 노드를 다른 유형으로 up / down 가능
단독으로 up / down 가능은 체크 필요
Shards
하나의 샤드에는 1~6개의 노드로 구성되며, primary 1개에 5개의 replica 로 구성
MemoryDB Cluster는 항상 적어도 하나의 샤드로 구성
클러스터 내 최대 500개의 샤드를 생성 가능
최대 500개 노드를 가질 수 있으므로, 1샤드=1 Primary 노드로 하는 경우 500샤드 구성 가능
단, IP주소가 충분한지 체크 필요
Parameter groups
parameter group 을 적용함으로써 각기 다른 parameter 를 적용 가능
RDS 와 동일 개념
Subnet Groups
VPC 내 subnet group 으로 구성
Access Control Lists
Redis ACL 규칙을 적용 가능 (Access Control List)
Users
이름과 암호를 가진 User를 생성하여 접속 가능
2. 사용자는 ACL 구성원
Redis vs Elasticache Redis vs MemoryDB for Redis
성능 : Elasticache 가 Memory DB 보다 쓰기 읽기 성능이 더 좋음
Redis
ElastiCache for Redis
MemoryDB for Redis
내구성
AOF, RDB 로 내구성 처리 (AOF 파일에 쓰기 전 장애 시 데이터 손실 발생 가능성)
Primary 리턴 응답이라, Replica node에 데이터 적재 전 장애 시 손실 발생 가능성 존재 Redis 데이터구조 및 API
내구성이 뛰어난 Inmemory DB (장애 시 무손실 복구) (Transaction log 까지 작성 후 응답이기 때문에 무손실 가능) Redis 데이터구조 및 API
성능
12만/sec
read/write :μs (마이크로초)
read :μs (마이크로초) write : ms (한자리 Millisecond)
Cluster mode
Cluster mode 활성화 비활성화 모두 가능
cluster mode 활성화, 비활성화 모두 가능
cluster mode 활성화 필수
접속
redis-cli 로 접속
백업
조건부 RDB 백업 가능
AOF 로 모든 DML 쿼리 저장
24시간 동안 20개까지 스냅샷 생성 제한
cluster mode에서만 백업
해당 Region에서 수동 스냅샷 보유 개수 제한은 없음
24시간 동안 20개까지 스냅샷 생성 제한
cluster mode에서만 백업
해당 Region에서 수동 스냅샷 보유 개수 제한은 없음
복원
RDB 시점 복원 가능
AOF 이용하여 원하는 명령문까지 복원 가능
RDB 스냅샷 복원
별도의 Replica node가 없을 경우 유실(마지막 스냅샷 이후 부터 유실)
RDB 스냅샷 복원
특정시점복원은 불가 (Point in time Recovery 불가)
Transaction log를 이용하여 장애 최종 복원 가능
고가용성
replica shard 구성
Replica Shard 구성
replica node의 복제가 실패하는 경우
실패 노드를 감지하여 오프라인 전환 및 동일한 AZ에 교체노드를 실행하여 동기화 진행
MemoryDB Multi-AZ primary 장애
MemoryDB에서 Primary 오류 감지하면, replica node들 중 primary 정합성체크 후 primary 승격 후 다른 AZ에 있는 primary를 spin up 이후 동기화 진행 (다른 AZ의 primary 를 spin up 이후 동기화 하는 것보다 더 빠름)
US East (N. Virginia), US East (Ohio), US West (Oregon), US West (Northern California), EU (Ireland), EU (London), EU (Stockholm), Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), and South America (Sao Paulo) - 21년10월 정보
메모리 DB (높은 처리량 - Replication 읽기 및 쓰기, 대기 시간 등 높은 처리 가능)
레디스와 호환이 되며, 레디스 관련한 것들을 모두 사용 가능 (v6.2)
Multi-AZ 를 지원하여 빠르게 failover 및 복구, 재시작이 가능
특징
Primary / Replica 간의 강력한 일관성 보장
ms 단위의 읽기,쓰기 지연시간 (클러스터당 최대 1억6천만 tps)
redis 호환
빠른 데이터 복구 및 재시작 제공 (multi-az, transaction log )
multi-az를 통한 자동 페일오버 및 노드 fail에 대한 감지 및 복구
replication 및 shard를 이용한 노드 추가, scale out, scale up-down 가능
primary 에 대한 read/write 일관성 보장 및 복제 노드에 대한 일관성 보장 가능(read / write concern으로 예상)
사용자 인증 및 네트워크 인증, 암호화 기능 제공
s3로 자동 스냅샷 (최대 35일 - rds 와 동일)
하나의 클러스터로 최대 500개 노드 및 100tb 이상의 storage 지원(레플리카 포함)
AWS KMS keys를 사용한 TLS 암호화(8번과 동일)
Redis를 통한 사용자 인증 및 권한 부여(ACL)(8번과 동일)
AWS Graviton2 인스턴스 유형 지원
VPC, Cloudwatch, CloudTrail, AWS SNS 서비스와의 통합
완전 관리형 소프트웨어 패치 및 업그레이드 지원
관리 API를 위한 AWS IAM(Identity and Access Management) 통합 및 태그 기반 액세스 제어
주요 기능
Cluster
MemoryDB 서비스를 운영하는 하나 이상의 노드 모음 (서비스의 개념)
Shard는 Memory DB Set 단위들의 모임으로 Cluster 내에 존재
Noes ⊂ Shard ⊂ Cluster = 서비스 DB
Memory DB Set 에는 하나의 Primary 와 최대 5개의 Replica 노드들을 보유 가능
Primary 는 read/write 가능하며, Replica node들은 only read 만 처리
Primary 장애 시 replica node들 중 하나를 primary 로 승격
cluster 생성 시 redis 버전을 지정
cluster 내 Memory DB 기능
cluster 추가
cluster 수정
cluster 스냅샷 가져오기
cluster 삭제
cluster 내 요소 보기
cluster 에 비용 할당 태그 추가 / 삭제
Nodes
MemoryDB 구성 중 가장 작은 단위 (EC2 기반)
클러스터에 속하며, cluster 생성 시 정해진 버전의 엔진 기반
필요한 경우 클러스터의 노드를 다른 유형으로 up / down 가능
단독으로 up / down 가능은 체크 필요
Shards
하나의 샤드에는 1~6개의 노드로 구성되며, primary 1개에 5개의 replica 로 구성
MemoryDB Cluster는 항상 적어도 하나의 샤드로 구성
클러스터 내 최대 500개의 샤드를 생성 가능
최대 500개 노드를 가질 수 있으므로, 1샤드=1 Primary 노드로 하는 경우 500샤드 구성 가능
단, IP주소가 충분한지 체크 필요
Parameter groups
parameter group 을 적용함으로써 각기 다른 parameter 를 적용 가능
RDS 와 동일 개념
Subnet Groups
VPC 내 subnet group 으로 구성
Access Control Lists
Redis ACL 규칙을 적용 가능 (Access Control List)
Users
이름과 암호를 가진 User를 생성하여 접속 가능
2. 사용자는 ACL 구성원
Redis vs Elasticache Redis vs MemoryDB for Redis
성능 : Elasticache 가 Memory DB 보다 쓰기 읽기 성능이 더 좋음
Redis
ElastiCache for Redis
MemoryDB for Redis
내구성
AOF, RDB 로 내구성 처리 (AOF 파일에 쓰기 전 장애 시 데이터 손실 발생 가능성)
Primary 리턴 응답이라, Replica node에 데이터 적재 전 장애 시 손실 발생 가능성 존재 Redis 데이터구조 및 API
내구성이 뛰어난 Inmemory DB (장애 시 무손실 복구) (Transaction log 까지 작성 후 응답이기 때문에 무손실 가능) Redis 데이터구조 및 API
성능
12만/sec
read/write :μs (마이크로초)
read :μs (마이크로초) write : ms (한자리 Millisecond)
Cluster mode
Cluster mode 활성화 비활성화 모두 가능
cluster mode 활성화, 비활성화 모두 가능
cluster mode 활성화 필수
접속
redis-cli 로 접속
백업
조건부 RDB 백업 가능
AOF 로 모든 DML 쿼리 저장
24시간 동안 20개까지 스냅샷 생성 제한
cluster mode에서만 백업
해당 Region에서 수동 스냅샷 보유 개수 제한은 없음
24시간 동안 20개까지 스냅샷 생성 제한
cluster mode에서만 백업
해당 Region에서 수동 스냅샷 보유 개수 제한은 없음
복원
RDB 시점 복원 가능
AOF 이용하여 원하는 명령문까지 복원 가능
RDB 스냅샷 복원
별도의 Replica node가 없을 경우 유실(마지막 스냅샷 이후 부터 유실)
RDB 스냅샷 복원
특정시점복원은 불가 (Point in time Recovery 불가)
Transaction log를 이용하여 장애 최종 복원 가능
고가용성
replica shard 구성
Replica Shard 구성
replica node의 복제가 실패하는 경우
실패 노드를 감지하여 오프라인 전환 및 동일한 AZ에 교체노드를 실행하여 동기화 진행
MemoryDB Multi-AZ primary 장애
MemoryDB에서 Primary 오류 감지하면, replica node들 중 primary 정합성체크 후 primary 승격 후 다른 AZ에 있는 primary를 spin up 이후 동기화 진행 (다른 AZ의 primary 를 spin up 이후 동기화 하는 것보다 더 빠름)
US East (N. Virginia), US East (Ohio), US West (Oregon), US West (Northern California), EU (Ireland), EU (London), EU (Stockholm), Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), and South America (Sao Paulo) - 21년10월 정보
더불어 문서에 앞서 ST Unitas 황선규님에게 감사 인사 드립니다. 대부분의 코딩 수정을 도와주셨습니다. (거의 다 작성해 주셨습니다 ㅎㅎ)
목적
Cloudwatch 상에서 확인할 수 있는 그래프를 Slack에서 이미지로 확인
가독성이 높아져서 현상 확인하기 쉬움
그래프를 확인하기 위해 AWS에 접속하는 불편 감수
동작방식
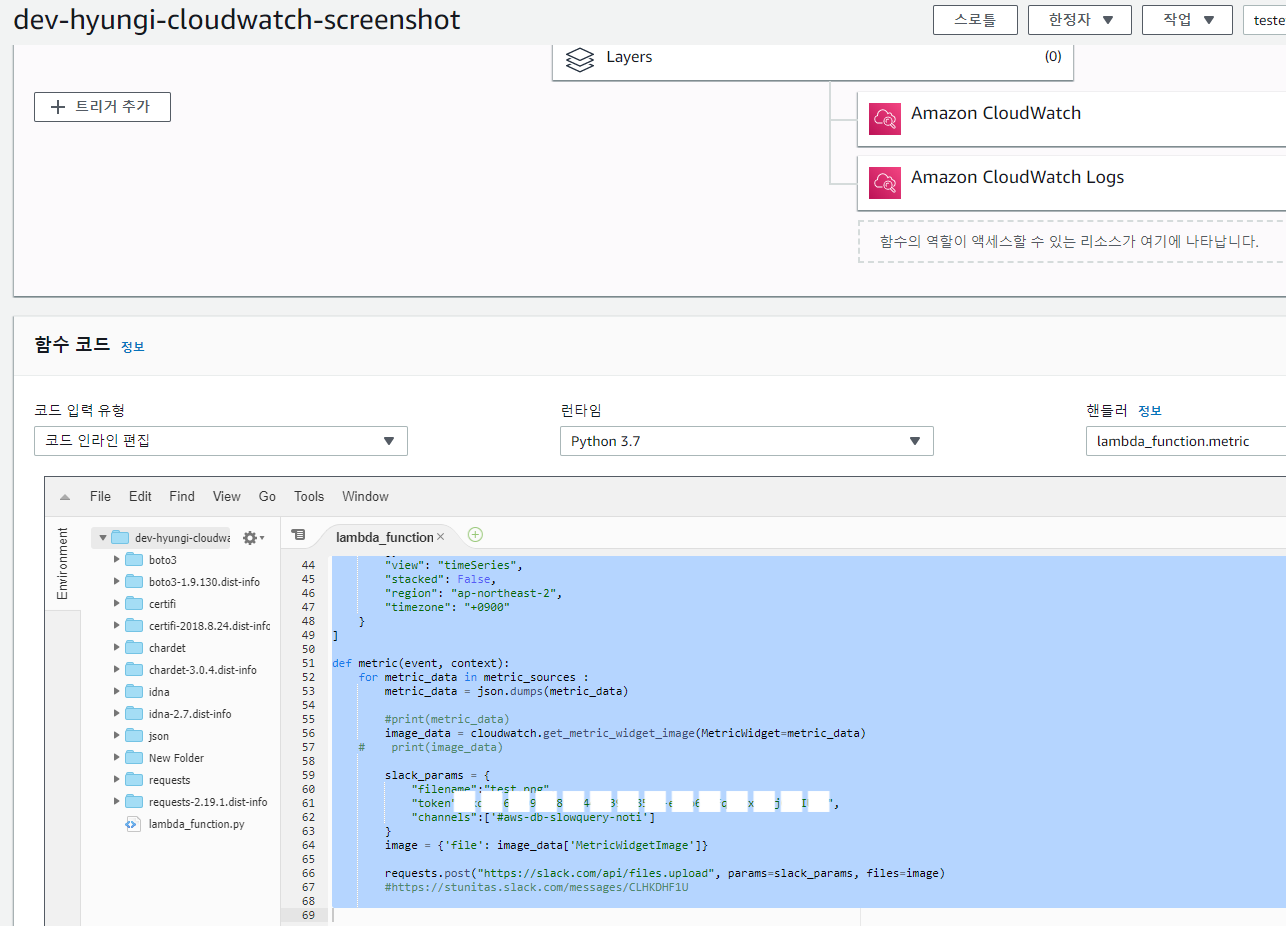
Lambda 에서 미리 셋팅한 Cloudwatch 정보를 이용하여(json) 현재 상태를 이미지화 하여 Slack으로 전송
Python 3.7로 개발
필요한 모듈
boto3
certifi
chardet
idna
json
requests
사전지식
Lambda 를 이용하기 위해서는 python에서 사용하는 모든 모듈을 파일로 보유해야함(모두 하나의 zip으로 압축해서 업로드) (Lambda에 대한 사전 지식이 있으면 괜찮지만, 처음 접하기에 쉽지 않음 - pip로 local로 필요한 모듈을 설치 후 해당 모듈의 폴더 전체가 필요) ex) C:\Users\접속한계정\AppData\Local\Programs\Python\Python37\Lib\site-packages 에 설치한 모듈 존재
Lambda 테스트를 위해서는 핸들러의 명칭에 존재하는 함수가 반드시 명시되어 있어야 하며, 함수의 Default 핸들러는 수정하면 안됨
권한 : boto3.client('cloudwatch').get_metric_widget_image 을 사용하기 위해서는 Cloudwatch에 접근할 수 있는 권한과 함께 "cloudwatch:GetMetricWidgetImage" 이라는 권한도 필요 Lambda를 생성하는 계정에 모든 권한이 존재 하더라도, Lambda 하단의 역할에서 존재 여부를 체크 필요 IAM 권한에서 있는지 여부 체크 필요 (아래는 관련 모든 권한을 부여함)
{
"Version":"2012-10-17",
"Statement": [
{
"Sid":"VisualEditor0",
"Effect":"Allow",
"Action": [
"cloudwatch:DescribeAlarmHistory",
"cloudwatch:GetDashboard",
"cloudwatch:GetMetricData",
"cloudwatch:DescribeAlarmsForMetric",
"cloudwatch:DescribeAlarms",
"cloudwatch:GetMetricStatistics",
"cloudwatch:GetMetricWidgetImage"
],
"Resource":"*"
}
]
}
필요한 Cloudwatch 정보
이미지로 보고자 하는 Cloudwatch 지표를 확인하여 저장 아래 샘플은 Cloudwatch의 지표 중 하나인 전체 EC2 CPU 정보
Slack 으로 전달하기 위해서 token 정보 필요 Slack bot을 미리 생성하였기 때문에 해당 Slack bot을 이용하였으며, channels 만 변경 한다면 동일 Bot을 이용해도 문제 없을 것이라고 예상 아래에서 channels 에서 필요한 곳으로 변경 하자.
slack_params = {
"filename":"test.png",
"token":"SLACK BOT의 token 값을 넣어 주시면 됩니다",
"channels":['#aws-db-slowquery-noti <-와 같이 채널 명칭을 넣어주세요.']
}
전체 소스
metric_sources 만 수정하면 된다. 디테일하게 수정하고 싶다하면 아래 문서 참조
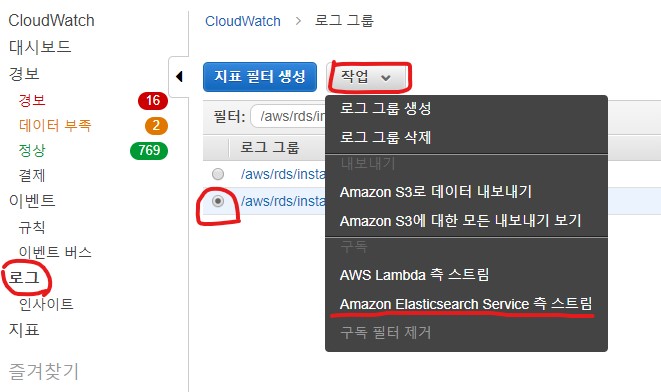
1. Cloudwatch의 로그 목록 선택 후 (slow query 선택 후 Elasticsearch Service 측 스트림 선택)
2. 생성한 ES 선택(Elasticsearch Service)
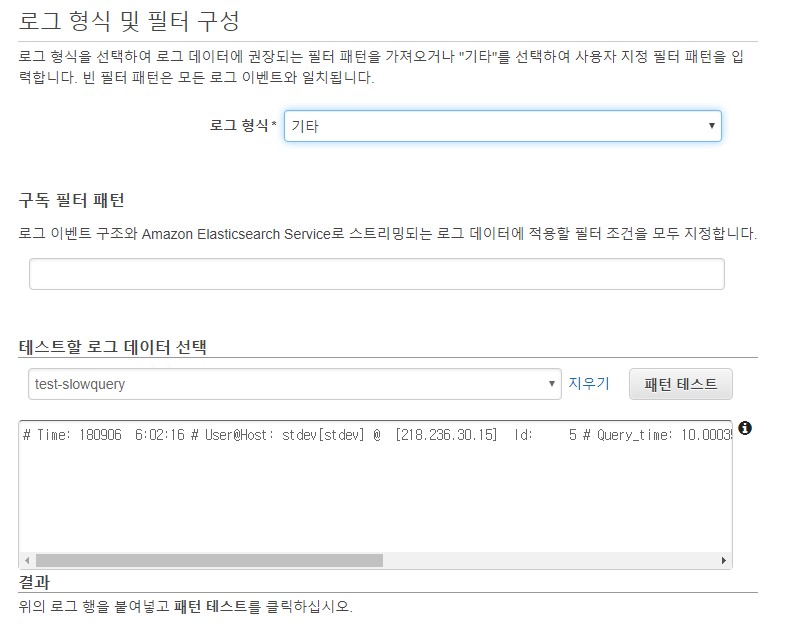
3. 로그 형식 및 필터 구성 시 기타로 설정 기타로 선택하는 이유는 여기서 필터패턴을 하게 되면 Slowquery의 여러 형태로 인해 원치 않은 데이터가 다른 형태로 필터가 되는 현상 발생 또한, cloudwatch 로그 형식 필터에서 아직까지 정규화 표현식을 제공하지 않으므로 slowquery를 필터 적용하기에는 맞지 않음(띄어쓰기 필터 등만 지원)
4. 이후 별다른 설정 없이진행(스트리밍 시작)
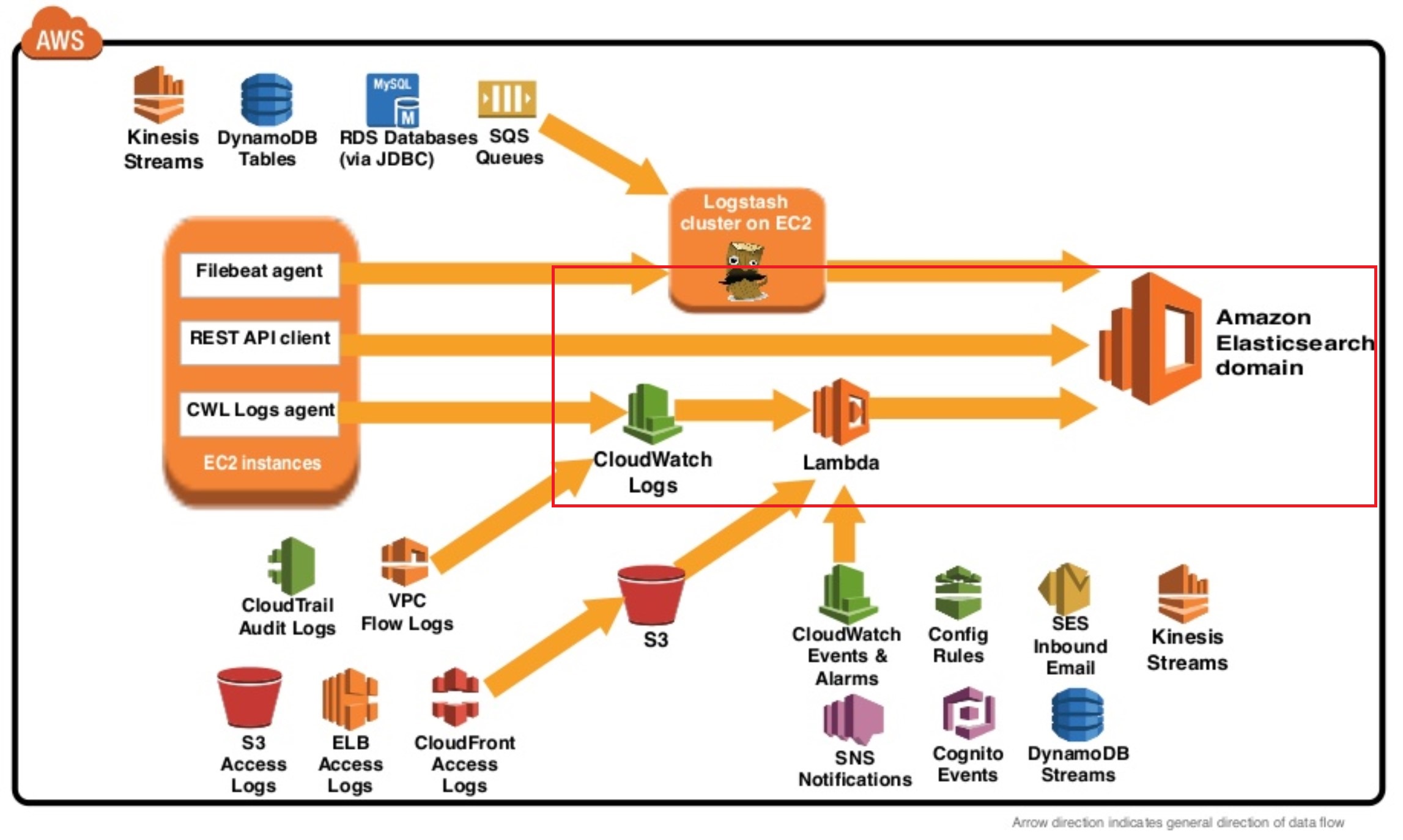
- 구독되고 있는것을 확인 가능(여기서 중요한 것은 모든 cloudwatch 를 이용해서 ES 로 보내는 작업-비단 Slowquery 뿐만 아니라 모든 작업/ 은 동일한 Lambda호출/ 2번의 캡쳐 화면을 보면 Lambda함수에 대한 내용이 있음)
하지만 Cloudwatch에서 제공하는 필터는 RDS slowquery 형태에 맞지 않습니다. 더군다나 쿼리들마다 형태가 다르다 보니 정영화 되지 않은 데이터를 일괄적인 형태로 보여지는 것에 대해서는 한계가 있더군요.
더불어 여러 RDS에서 들어오는 slowquery를 AWS에서 제공하는 하나의 lambda(node.js) 에서만 처리가 되니 어느 DB에서 생긴 slowquery인지 확인이 어렵더군요.
다행히, AWS Support 에 문의 하였더니 Lambda 수정의 방법과 기존 고려했던 export 받은 후 처리 2가지 방법을 제시하였으며, Lambda의 경우 친절하게 수정한 코더도 주시더군요!!!
하지만, Lambda 수정은 제 몫이기에 처음으로 접해보는 node.js를 잡고 끙끙대기 시작했습니다.
console.log 를 이용한 일일이 로그 찍어가며 테스트하며 수정을 했습니다.
아래는 수정한 Lambda입니다. 개발자 분들이 보시면 얼마나 욕할지...ㅠㅠ하지만 저는 개발자가 아니기에...당당히 소스를 공유 합니다.
수정하셔도 되고 그대로 적용하셔도 됩니다.(무슨 근자감...)
수정 부분은 2군데 입니다.
1. 여기는 rds의 네임을 cwl 뒤에 작성해 줌으로서 구분이 가능해 집니다.(AWS Jihyun B. 님이 제공)
// index name format: cwl-YYYY.MM.DD Slowquery modify 1
/*
var indexName = [
'cwl-' + timestamp.getUTCFullYear(), // year
('0' + (timestamp.getUTCMonth() + 1)).slice(-2), // month
('0' + timestamp.getUTCDate()).slice(-2) // day
].join('.');
*/
var indexName = [
'cwl' + payload.logGroup.toLowerCase().split('/').join('-') + '-' + timestamp.getUTCFullYear(), // log group + year
('0' + (timestamp.getUTCMonth() + 1)).slice(-2), // month
('0' + timestamp.getUTCDate()).slice(-2) // day
].join('.');
2. 여기는 정규표현식을 이용하여 slow query 를 파싱 및 필터를 적용한 후 맵핑하는 곳입니다. 참고로 저는 node.js 는 처음이며, 정규표현식도 모릅니다..ㅠ그래서 하드 코딩을 했는데...동적으로 코딩 하기에는 머리가 안돌아가서 그냥 포기했습니다. 이쁘게 사용하실 분은 수정하셔도 됩니다.
message는 slow 쿼리의 전문이 들어오는 곳이며, extractedFields 는 맵핑하는 형태가 들어오는 곳인데, 우리가 필터를 기타로 한 후 작성안하고 넘기기 때문에 if 문에 걸리지 않고 else 로 빠지는 것입니다.
function buildSource(message, extractedFields) {
...
if 문 끝에 else로 추가
...
//Slowquery add
else {
console.log('Slow query Regular expression')
var qualityRegex = /User@Host: ([^&@]+) /igm;
var ipRegex = /\d+\.\d+\.\d+\.\d+/igm;
var querytimeReg = /Query_time: ([^& ]+)/igm;
var locktimeReg = /Lock_time: ([^& ]+)/igm;
var querytimeReg = /Query_time: ([^& ]+)/igm;
var rowsentReg = /Rows_sent: ([\d^&]+)/igm;
var rowexaminedReg = /Rows_examined: ([\d^&]+)/igm;
var slowqueryReg = /select ([^&;]+)|update ([^&;]+)|delete ([^&;]+)/igm;
var userhost, ip, querytime, querylock, rowsent, rowexaminge, slowquery ='';
var matches, qualities = [];
var source = {};
while (matches = qualityRegex.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
userhost = qualities[0];
ip = ipRegex.exec(message)[0];
matches, qualities = [];
while (matches = querytimeReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
querytime = qualities[0];
matches, qualities = [];
while (matches = locktimeReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
querylock = qualities[0];
matches, qualities = [];
while (matches = rowsentReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
rowsent = qualities[0];
matches, qualities = [];
while (matches = rowexaminedReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
rowexamined = qualities[0];
slowquery = slowqueryReg.exec(message)[0];
console.log(userhost);
console.log(ip);
console.log(querytime);
console.log(querylock);
console.log(rowsent);
console.log('hyungi rowexaminge: ',rowexamined);
console.log('hyungi query :',slowquery);
source['User@Host'] = userhost;
source['IP'] = ip;
source['Query_time'] = 1 * querytime;
source['Lock_time'] = 1 * querylock;
source['Rows_sent'] = 1 * rowsent;
source['Rows_examined'] = 1 * rowexamined;
source['Query'] = slowquery;
console.log('Slow query Filter complete : ', source)
return source;
}
아래는 전체 Lambda 소스 입니다.( LogsToElasticsearch_st-elk-slowquery )
// v1.1.2
var https = require('https');
var zlib = require('zlib');
var crypto = require('crypto');
var endpoint = 'search-st-elk-slowquery-edn6wa74e2h3zchmep6lbu2xky.ap-northeast-2.es.amazonaws.com';
// Set this to true if you want to debug why data isn't making it to
// your Elasticsearch cluster. This will enable logging of failed items
// to CloudWatch Logs.
var logFailedResponses = false;
exports.handler = function(input, context) {
// decode input from base64
var zippedInput = new Buffer.from(input.awslogs.data, 'base64');
// decompress the input
zlib.gunzip(zippedInput, function(error, buffer) {
if (error) { context.fail(error); return; }
// parse the input from JSON
var awslogsData = JSON.parse(buffer.toString('utf8'));
// transform the input to Elasticsearch documents
var elasticsearchBulkData = transform(awslogsData);
// skip control messages
if (!elasticsearchBulkData) {
console.log('Received a control message');
context.succeed('Control message handled successfully');
return;
}
// post documents to the Amazon Elasticsearch Service
post(elasticsearchBulkData, function(error, success, statusCode, failedItems) {
console.log('Response: ' + JSON.stringify({
"statusCode": statusCode
}));
if (error) {
logFailure(error, failedItems);
context.fail(JSON.stringify(error));
} else {
console.log('Success: ' + JSON.stringify(success));
context.succeed('Success');
}
});
});
};
function transform(payload) {
if (payload.messageType === 'CONTROL_MESSAGE') {
return null;
}
var bulkRequestBody = '';
payload.logEvents.forEach(function(logEvent) {
var timestamp = new Date(1 * logEvent.timestamp);
// index name format: cwl-YYYY.MM.DD Slowquery modify 1
/*
var indexName = [
'cwl-' + timestamp.getUTCFullYear(), // year
('0' + (timestamp.getUTCMonth() + 1)).slice(-2), // month
('0' + timestamp.getUTCDate()).slice(-2) // day
].join('.');
*/
var indexName = [
'cwl' + payload.logGroup.toLowerCase().split('/').join('-') + '-' + timestamp.getUTCFullYear(), // log group + year
('0' + (timestamp.getUTCMonth() + 1)).slice(-2), // month
('0' + timestamp.getUTCDate()).slice(-2) // day
].join('.');
var source = buildSource(logEvent.message, logEvent.extractedFields);
source['@id'] = logEvent.id;
source['@timestamp'] = new Date(1 * logEvent.timestamp).toISOString();
source['@message'] = logEvent.message;
source['@owner'] = payload.owner;
source['@log_group'] = payload.logGroup;
source['@log_stream'] = payload.logStream;
var action = { "index": {} };
action.index._index = indexName;
action.index._type = payload.logGroup;
action.index._id = logEvent.id;
bulkRequestBody += [
JSON.stringify(action),
JSON.stringify(source),
].join('\n') + '\n';
});
return bulkRequestBody;
}
function buildSource(message, extractedFields) {
if (extractedFields) {
var source = {};
for (var key in extractedFields) {
if (extractedFields.hasOwnProperty(key) && extractedFields[key]) {
var value = extractedFields[key];
if (isNumeric(value)) {
source[key] = 1 * value;
continue;
}
jsonSubString = extractJson(value);
if (jsonSubString !== null) {
source['$' + key] = JSON.parse(jsonSubString);
}
source[key] = value;
}
}
return source;
}
//Slowquery add
else {
console.log('Slow query Regular expression')
var qualityRegex = /User@Host: ([^&@]+) /igm;
var ipRegex = /\d+\.\d+\.\d+\.\d+/igm;
var querytimeReg = /Query_time: ([^& ]+)/igm;
var locktimeReg = /Lock_time: ([^& ]+)/igm;
var querytimeReg = /Query_time: ([^& ]+)/igm;
var rowsentReg = /Rows_sent: ([\d^&]+)/igm;
var rowexaminedReg = /Rows_examined: ([\d^&]+)/igm;
var slowqueryReg = /select ([^&;]+)|update ([^&;]+)|delete ([^&;]+)/igm;
var userhost, ip, querytime, querylock, rowsent, rowexaminge, slowquery ='';
var matches, qualities = [];
var source = {};
while (matches = qualityRegex.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
userhost = qualities[0];
ip = ipRegex.exec(message)[0];
matches, qualities = [];
while (matches = querytimeReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
querytime = qualities[0];
matches, qualities = [];
while (matches = locktimeReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
querylock = qualities[0];
matches, qualities = [];
while (matches = rowsentReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
rowsent = qualities[0];
matches, qualities = [];
while (matches = rowexaminedReg.exec(message)) {
qualities.push(decodeURIComponent(matches[1]));
}
rowexamined = qualities[0];
slowquery = slowqueryReg.exec(message)[0];
console.log(userhost);
console.log(ip);
console.log(querytime);
console.log(querylock);
console.log(rowsent);
console.log('hyungi rowexaminge: ',rowexamined);
console.log('hyungi query :',slowquery);
source['User@Host'] = userhost;
source['IP'] = ip;
source['Query_time'] = 1 * querytime;
source['Lock_time'] = 1 * querylock;
source['Rows_sent'] = 1 * rowsent;
source['Rows_examined'] = 1 * rowexamined;
source['Query'] = slowquery;
console.log('Slow query Filter complete : ', source)
return source;
}
jsonSubString = extractJson(message);
if (jsonSubString !== null) {
return JSON.parse(jsonSubString);
}
return {};
}
function extractJson(message) {
var jsonStart = message.indexOf('{');
if (jsonStart < 0) return null;
var jsonSubString = message.substring(jsonStart);
return isValidJson(jsonSubString) ? jsonSubString : null;
}
function isValidJson(message) {
try {
JSON.parse(message);
} catch (e) { return false; }
return true;
}
function isNumeric(n) {
return !isNaN(parseFloat(n)) && isFinite(n);
}
function post(body, callback) {
var requestParams = buildRequest(endpoint, body);
var request = https.request(requestParams, function(response) {
var responseBody = '';
response.on('data', function(chunk) {
responseBody += chunk;
});
response.on('end', function() {
var info = JSON.parse(responseBody);
var failedItems;
var success;
var error;
if (response.statusCode >= 200 && response.statusCode < 299) {
failedItems = info.items.filter(function(x) {
return x.index.status >= 300;
});
success = {
"attemptedItems": info.items.length,
"successfulItems": info.items.length - failedItems.length,
"failedItems": failedItems.length
};
}
if (response.statusCode !== 200 || info.errors === true) {
// prevents logging of failed entries, but allows logging
// of other errors such as access restrictions
delete info.items;
error = {
statusCode: response.statusCode,
responseBody: info
};
}
callback(error, success, response.statusCode, failedItems);
});
}).on('error', function(e) {
callback(e);
});
request.end(requestParams.body);
}
function buildRequest(endpoint, body) {
var endpointParts = endpoint.match(/^([^\.]+)\.?([^\.]*)\.?([^\.]*)\.amazonaws\.com$/);
var region = endpointParts[2];
var service = endpointParts[3];
var datetime = (new Date()).toISOString().replace(/[:\-]|\.\d{3}/g, '');
var date = datetime.substr(0, 8);
var kDate = hmac('AWS4' + process.env.AWS_SECRET_ACCESS_KEY, date);
var kRegion = hmac(kDate, region);
var kService = hmac(kRegion, service);
var kSigning = hmac(kService, 'aws4_request');
var request = {
host: endpoint,
method: 'POST',
path: '/_bulk',
body: body,
headers: {
'Content-Type': 'application/json',
'Host': endpoint,
'Content-Length': Buffer.byteLength(body),
'X-Amz-Security-Token': process.env.AWS_SESSION_TOKEN,
'X-Amz-Date': datetime
}
};
var canonicalHeaders = Object.keys(request.headers)
.sort(function(a, b) { return a.toLowerCase() < b.toLowerCase() ? -1 : 1; })
.map(function(k) { return k.toLowerCase() + ':' + request.headers[k]; })
.join('\n');
var signedHeaders = Object.keys(request.headers)
.map(function(k) { return k.toLowerCase(); })
.sort()
.join(';');
var canonicalString = [
request.method,
request.path, '',
canonicalHeaders, '',
signedHeaders,
hash(request.body, 'hex'),
].join('\n');
var credentialString = [ date, region, service, 'aws4_request' ].join('/');
var stringToSign = [
'AWS4-HMAC-SHA256',
datetime,
credentialString,
hash(canonicalString, 'hex')
] .join('\n');
request.headers.Authorization = [
'AWS4-HMAC-SHA256 Credential=' + process.env.AWS_ACCESS_KEY_ID + '/' + credentialString,
'SignedHeaders=' + signedHeaders,
'Signature=' + hmac(kSigning, stringToSign, 'hex')
].join(', ');
return request;
}
function hmac(key, str, encoding) {
return crypto.createHmac('sha256', key).update(str, 'utf8').digest(encoding);
}
function hash(str, encoding) {
return crypto.createHash('sha256').update(str, 'utf8').digest(encoding);
}
function logFailure(error, failedItems) {
if (logFailedResponses) {
console.log('Error: ' + JSON.stringify(error, null, 2));
if (failedItems && failedItems.length > 0) {
console.log("Failed Items: " +
JSON.stringify(failedItems, null, 2));
}
}
}
이렇게 하면 Elastisearch 에서 index 가 생성 되었는지 체크하면 됩니다.
-Slowquery 가 발생해야 생성이 되므로 Lamdba 까지 수정이 완료 되었다면 제대로 들어 오는지 체크를 위해 DB에서 select sleep(30); 으로 슬로우 쿼리 생성 진행 - Lamdba 가 호출 되어서 진행 되었는지 Cloudwatch 통해서 확인 가능(수정한 Lamdba 로그가 생성 되었는지 체크도 가능