사내 서비스 중 Redis 에서 Lua 를 많이 사용하여 이번 기회에 Lua 메모리 관련하여 정리해 보았습니다.
Lua 스크립트란 ?
- 스크립트 언어로써, 문자열 함수와 수학 함수를 제공
- 그래픽 시뮬레이션을 위한 스크립트 언어로 개발된 언어로써 타 스크립트 언어보다 빠른 성능을 제공
- 변수를 제거하거나 미리 선언을 위한 별도의 처리가 필요 없음
Redis 에서 Lua 스크립트
- 프로그래밍 방식 제어구조를 사용하고 db에 access 하여 실행하는 대부분의 명령을 사용 가능
- redis.call('set', key, value) 형태
- 지역 변수를 사용해야 함
- ex) 변수 선언 시 : local src = keys[1]
- eval 명령어를 이용하여 수행하고자 하는 스크립트를 redis로 전송하여 사용 가능
- script load 명령을 이용하여 redis server에 등록 시킨 후 사용 가능
- 데이터가 존재하는 곳에서 실행되기 때문에 전체 대기 시간 뿐만 아니라 네트워크 리소스 절약 가능
- Application 로직의 일부를 Redis 내에서 실행이 가능하며 여러키에 걸쳐 조건부 업데이트 수행 가능하며 다른 데이터 유형을 함께 처리도 가능
- Script는 Lua 엔진(Lua5.1) 에 의해 실행
- 기본적으로 Eval script는 클라이언트 일부로 간주하기 때문에 서버에 persistence 하게(영구) 저장이 되지 않기에(단순 Caching-휘발성), Redis server가 재시작 되거나 한다면 re-Load 해야 함
- 7.0에서 부터는 redis function 추가 프로그래밍 로직으로 서버 자체를 확장할 수 있는 프로그래밍 가능성에 의해 persitence 하게 저장이 가능 (모든 client에서 사용이 가능)
- 7.0 부터는 read-only script 가 가능 (read replica에서 지원)
- https://redis.io/docs/manual/programmability/
- 메모리 각 내용
- used_memory_lua : Lua 엔진에 의해 사용된 메모리 크기 (byte)
- used_memory_scripts : 5.0 추가 (mh->lua_caches) 생성된 루아 스크립트가 사용하는 메모리 양
- 모니터링 진행 할 때 used_memory_scripts 를 확인하면 되며, set 명령어만 이루어진 스크립트는 별도로 used_memory_scripts 영역이 변경되지 않음
- redis server에서 실행되는 lua script는 원자성(Atomicity)하게 처리된다. (lua가 실행되는 동안 다른 레디스 명령어는 실행 안되는 것을 의미-다른 모든 명령어 차단)
- 이 부분은 single thread 때문이 아닐까...
- 스크립트 내용이 동일한 동작!!!을 하더라도, 조금이라도 다르다면 다른 스크립트로 인식 하기 때문에, 의미만 변경되는 스크립트 들에 대해서는 변수 처리로 하여 사용하면 캐싱 절약 효과를 얻을 수 있음
#아래는 동일한 동작을 하지만 내용이 다르기 때문에 서로 다른 내용으로 인식하여 used_memory_lua / used_memory_scripts 값 둘다 변경
eval "return 'hellow world?'" 0
eval "return 'hellow world????'" 0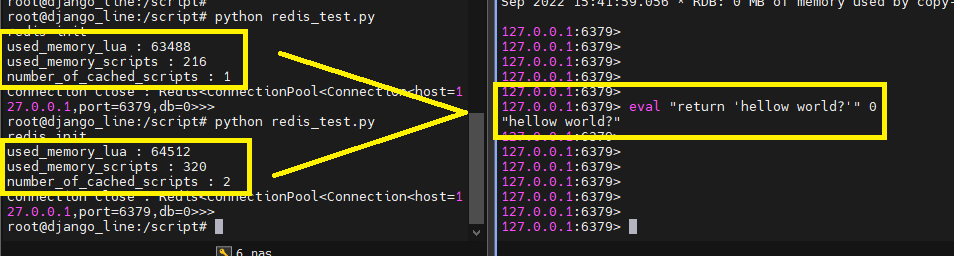

#아래는 동일한 내용을 호출한 경우 캐싱되어 있기 때문에 memory 변화값이 없음을 확인
eval "return 'hellow world????'" 0
eval "return 'hellow world????'" 0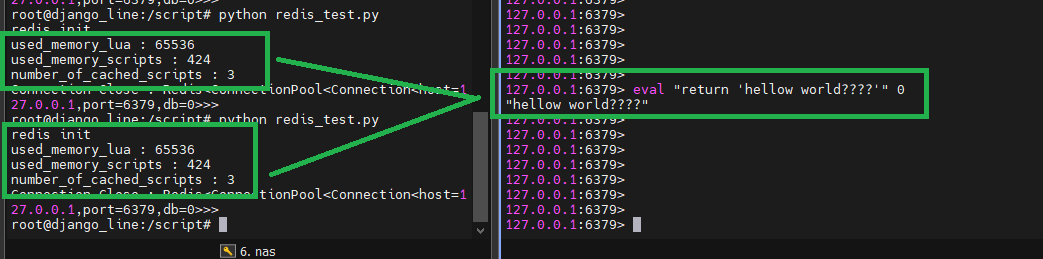
테스트 1.
이번에는 재밌는 테스트를 진행 하였다.
동일한 redis 구문이지만, return 을 하고 안하고의 차이 이다.
둘다 명령어는 get 명령어로 값을 리턴을 하지만, 이것을 결국 client까지 return을 하느냐 안 하느냐 차이일 것 같은데, 스크립트는 역시 이것을 다른 script로 인식을 하는 것을 확인
eval "redis.call('get', 'lua_test_2555')" 0
eval "return redis.call('get', 'lua_test_2555')" 0- 당연히 get 명령어이고 lua script를 호출이기 때문에 used_memory_scripts / used_memory_lua 모두 값이 변경 된 것을 확인할 수 있다.

- 이번에는 명령어는 동일하지만 return 을 하는 명령어 실행
- used_memory_scripts / used_memory_lua 모두 값이 변경 된 것을 확인할 수 있다.

- 당연하겠지만, 기존에 캐싱되어 있는 영역을 다시 조회 시
- used_memory_scripts / used_memory_lua 모두 값이 변경 되지 않은 것을 확인
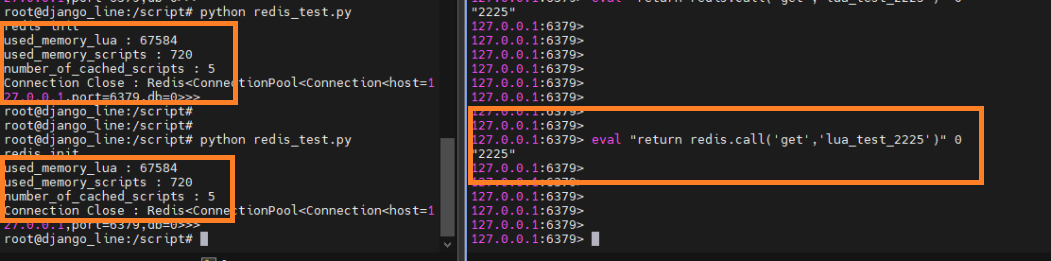
- 결국은 lua 는 내부 모두 동일해야 동일한 script로 인식하여 캐싱 여부를 사용할지 정하는 척도
- 데이터 변경이 일어나는 곳이라면 당연히 파라메터로 작성하여 사용 하는 것을 의미하며 이렇게 사용할 것을 권고
테스트 2.
- 추가로 set 명령어는 lua 엔진을 사용할 뿐, used_memory_scripts 의 값이 변경 되는 내역은 없음
- 기존 get 명령어나 return 하는 명령어의 경우 used_memory_scripts 값이 변경 되는 것을 확인할 수 있으나, 오로지 set 명령어의 경우 lua engine 의 값만 변경(used_memory_lua ) 되는 것을 확인 할 수 있다.
local src = KEYS[1]
for i=1, src, 2 do
local test_key = 'lua_test_' .. i
redis.call('set', test_key, i)
end;
-> 한마디로 set lua_test_홀수번호 홀수번호
EVAL "local src = KEYS[1] for i=1, src, 2 do local test_key = 'lua_test_' .. i redis.call('set', test_key, i) end;"- 초기 값 확인
- used_memory_lua : 32768 / used_memory_scripts : 0 / number_of_cached_scripts : 0
- lua 스크립트로 캐싱 진행
- used_memory_lua : 33792 / used_memory_scripts : 216 / number_of_cached_scripts : 1
- lua 엔진 및 메모리에 적재 된 것을 확인 (스크립트 등록 시 기본 동작 하는 것으로 확인)
- lua 스크립트 실행
- used_memory_lua : 63488 / used_memory_scripts : 216 / number_of_cached_scripts : 1
- lua 엔진은 사용하였지만, get 명령어 같이 조회 하거나 하는 것이 아니기 때문에 lua 메모리 쪽에 적재 되는 것은 없는 것으로 확인

- 다시 한번 lua 스크립트 실행
- 동일하게 lua 엔진은 사용하였지만, memory 는 사용 하지 않은 것을 확인
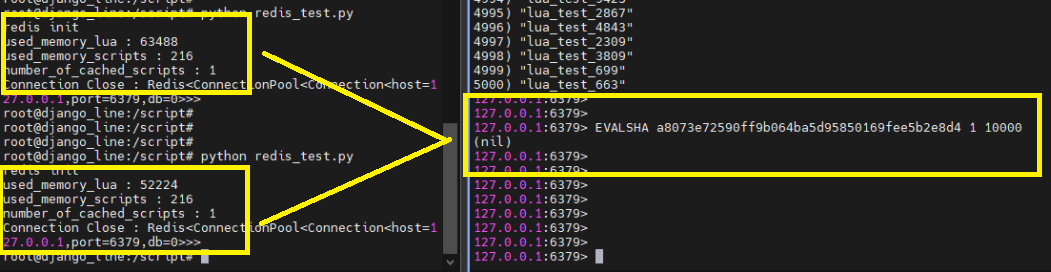
- 바로 lua 로 실행 하여도 동일하게 engine 은 사용하지만, memory는 변경 되지 않는 것을 확인 완료

- 동일하게 lua 엔진은 사용하였지만, memory 는 사용 하지 않은 것을 확인
결론
- 동일한 의미로 보이는 Lua 스크립트라고 하더라도, 내용이 조금이라도 다르면 서로 다른 스크립트로 인식
- 동일한 명령어 이라고 하더라도, return 의 유무에 따라 위의 의미와 같이 서로 다른 스크립트로 인식
- set 명령어로만 이루어진 lua 스크립트는, 별도의 메모리를 사용하지 않음 (lua 엔진만 메모리 사용)
- 그 외 메모리 사용률을 확인 하기 위해서는 used_memory_scripts 를 모니터링 하며, used_memory_lua 는 평소와 비슷한지 체크하면 좋을 듯 합니다.
- Elasticache 를 이용한다면, Lua script 내용이 get 형태의 읽기로만 이루어진 내용이라면, read를 이용하는 것을 추천합니다.(Lua의 수행속도가 오래 걸린다면 write 뿐만 아니라 redis 자체가 싱글 스레드로 동작하기 때문에 대기를 하게 되지만, 적어도 read를 이용한다면 write에 대해서만큼은 영향을 덜 미치기 때문 / 하지만 Lua 성능 최적화는 꼭 합시다.)
그외
AWS 의 경우 Cloudwatch 상에서 Elasticache 지표에서는 used_momory_scripts / lua 등을 제공을 하지 않기 때문에 BytesUsedForCache 와 FreeableMemory 의 변화로 모니터링 하는 것으로 우회 하거나, 해당 지표를 직접 조회하여 모니터링 하는 것을 추천 드립니다.
참고
다양한 샘플을 참고 할 수 있음 : https://bstar36.tistory.com/348
https://redis.io/docs/manual/programmability/eval-intro/
AWS Support 최원 님 도움 주셔서 감사합니다.
반응형
'Redis' 카테고리의 다른 글
| [redis] dump 파일 이용하여 json 파일 convert (2) | 2018.03.29 |
|---|---|
| [redis] 콘솔에서 redis 데이터 확인 (0) | 2018.03.23 |
| [Redis] Replication / Check 방법 (0) | 2018.02.19 |
| [Redis] 로그인 시 127.0.0.1:6379: Connection refused (2) | 2018.02.19 |
| [펌] [Redis] Redis란 ? 2번째 (1) | 2016.10.11 |






.png)



.png)

.png)

.png)


.png)

