fsync가 on이면, PostgreSQL서버는 fsync()시스템콜을 통해서 변경분을 디스크에 물리적으로 바로 쓴다. 이는 데이터베이스클러스터가 OS나 하드웨어 장애시 consistent한 상태로 복구가 가능함을 보장한다.
fsync를 off한다면, OS가 알아서 메모리에 있는 것을 디스크로 내려쓰게 된다. 언제 무엇이 디스크에 쓰여졌는지 아닌지 알수 없다. 그러므로 성능상 이득을 볼수는 있겠지만, 전원장애나 system crash로가 발생했을때 복구가 불가능할수 있다. 만약 전체 데이터베이스를 쉽게 재생성할수 있는 경우에만 off하도록 한다. 예를들어 백업본으로부터 새로운 데이터베이스 클러스트를 초기 구축하는 경우, 버리고 재생성할 데이터베이스의 데이터 처리, 자주 재생성되는 read-only 데이터베이스 복제본으로 failover에 사용되지 않는 데이터베이스인 경우 사용할 수 있다. 고성능의 하드웨어 장비라고해서 fsync를 끄는 것은 올바르지 않다.
성능을 위해서라면 synchronous_commit을 off하는 것만으로 충분할 것이다.
만약 off하기로 했다면, full_page_writes도 off하는 것을 고려하도록 한다.
WAL 를 사용하여, PITR 지원이 가능
WAL 를 재생하여 복구가 가능
Asynchronous Commit
DB Crash 발생 시, 가장 최근의 Transaction은 유실 가능성 존재(Risk)
다만, transaction 을 더 빠르게 처리가 가능
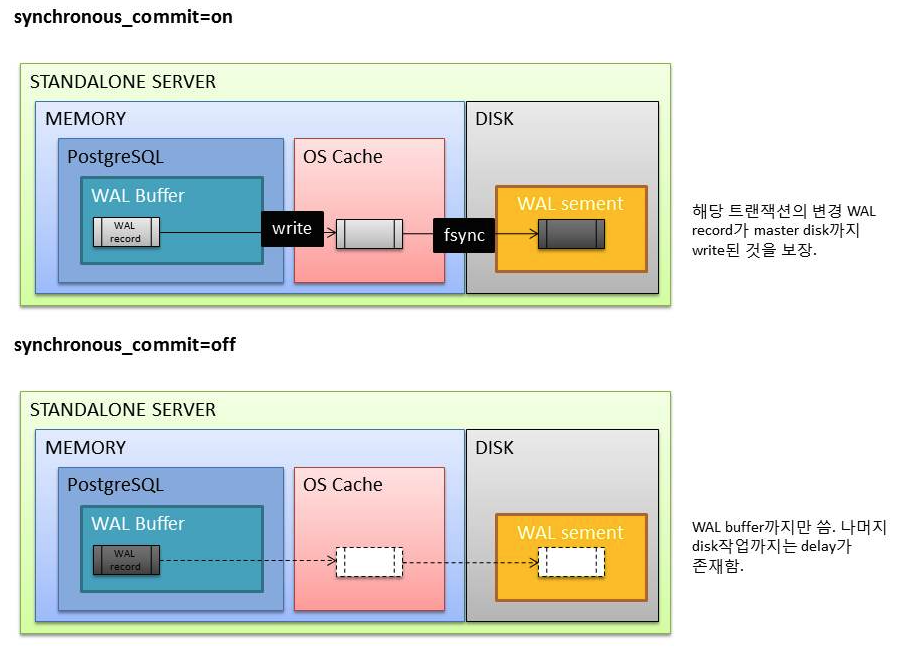
Default 는 synchronous (동기)
Client에 transaction result를 return 하기 전에, WAL 의 record가 Disk 에 write될 때까지 기다렸다가 ack 처리. -> commit 된 transaction 에 대한 무결성 보장을 의미
다만, 이것에 대한 비용은 발생
이러한 비용을 조금이라도 줄이기 위한 방법으로, disk flush 응답을 받기 전에 WAL buffer에서만 작성 후 ack 하는 방식을 Asynchronous Commit -> Transaction 처리량 향상
synchronous_commit Parameter 를 이용하여 수정이 가능하며, transaction 마다 설정이 가능
off : 클라이언트에 바로 transaction commit을 보냄. 하지만 실제로 트랜잭션이 안전하게 반영(WAL record가 WAL file에 쓰여짐) 되기까지 딜레이가 존재함. 서버 crash났을때 트랜잭션 손실될 수 있음. (최대 delay는 wal_writer_delay(200ms)의 3배). 하지만 fsync와는 달리 off로 한다고 해서 db 일관성에 문제가 되지는 않음. 최근 커밋되어야하는 트랜잭션이 손실될 수는 있으나 database 상태는 이 트랜잭션들이 정상적으로 롤백된 것과 같아서 일관성에 문제 없음.
DROP TABLE 은 synchronous_commit 와 상관없이 동기식으로 처리 : 일관성을 보장하기 위함.
PREPARE TRANSACTION 와 같은 2-phase commit 의 경우도 동기식으로 처리
wal_writer_delay ms 마다 WAL Writer 가 Disk 로 flush 진행
최대 유실 시간은 wal_writer_delay milliseconds * 3 의 risk 가 존재
busy periods(바쁜기간?)에 WAL writer 가 한 번에 Disk 로 flush 를 진행하는 것을 선호로 인해 발생 (정확한 의미는 모르겠습니다. 왜 wal_writer_delay 의 최대 3배의 시간으로 명시했는지.
commit_delay parameter 와 유사하지만, commit_delay 는 synchronous commit 의 방법에 속함
Asynchronous commit 을 설정하면, commit_delay 는 무시
commit_delay 는 transaction 이 WAL disk flush 지연을 유발
checkpoint 이후 각 Disk page를 수정(dml로 인해) 하는 도중에 해당 페이지의 전체 내용을 WAL 에 기록
os crash 발생 시, 진행 중인 페이지 쓰기가 부분적으로만 완료 되어 디스크 상의 페이지에 과거 데이터와 새 데이터가 공존하기 때문에, 복구 진행 시 올바른 복구가 보장되지만 WAL 에 기록하는 데이터량은 증가될 수 밖에 없음
checkpoint 간격을 늘릴 수 있음.
off 하면, 운영 속도가 향상되지만, 시스템 crash 발생 시, 손상된 데이터가 복구 불가능 또는 데이 손사이 발생 가능성 존재
fsync 를 해제했을 때와 유사
PITR 진행 시, WAL 아카이빙 사용에는 영향을 미치지 않음
postgresql.conf 파일 또는 command 로 설정 가능
checkpoint_timeout sec 마다 또는 max_wal_size 가 초과될 경우 checkpoint 발생
default : 5 min (300 sec) / 1 Gb
WAL 에 작성이 안된 경우 checkpoint_timeout 이 되어도 checkpoint 가 발생하지 않음
물론 CHECKPOINT 명령어로 강제 실행은 가능
만약 해당 변수 값들을 줄이며, 더 자주 checkpoint 발생 : DB crash 후 빠른 복구는 가능하지만 Disk I/O 비용 발생
full_page_writes 가 설정된 경우 (default 설정) , check point 발생 후 데이터 페이지 수정이 발생하는 경우 전체 페이지가 기록 -> 더 많은 Disk I/O 발생(시간을 짧게 가져갈수록 disk I/O는 더욱더 증가)
checkpoint_timeout 시간을 충분히 여유있게 가져가는 것을 책에서는 권장하며, checkpoint_warning 로 checkpoint 에 대해 sanity check (온전성 검사?)가 가능
당연하겠지만, checkpoint timeout 보다 더 잦은 checkpoinrt 가 발생하면 max_wal_size 증가 하라는 메시지가 log 에 남음
XLogInsertRecord
Shared memory 내 WAR buffer 에 new record 를 배치하는데 사용
만약 새로운 데이터가 insert 될 공간이 없으면, kernel cache 로 채워진 WAL buffer 일부를 move 시킴 -> 이것은 exclusive lock (대상 data page) 을 유발하기 때문에, 성능에 좋지 않음
일반적으로 XLogFlush 에 의해 WAL buffer 를 WAL file 에 flush 되어야 함.
wal_buffers 를 이용하여 WAL bufferpool 수를 조정 가능하며, full_page_writes 가 설정되어 있고, 시스템이 바쁜경우 wal_buffers 수를 늘려주는 것을 권장
XLogFlush
LogWrite 의 issue_xlog_fsync 의 호출에 의해 XLogFlush 가 WAL buffer 의 내용을 disk 로 flush
commit_delay
commit_delay (ms)는 XLogFlush 내에서 lock 을 획득 하는동안, group commit 을 기다리는 시간(지연시간) parameter
목적은 동시에 commit 되는 transaction 전체에 걸쳐 flush 작업의 비용을 분할할 수 있는 것(다만 transaction 시간은 증가)
commit_delay 가 발생하면, 대기하는 commit record들은 WAL Buffer 에 추가 하여 정합성을 지키는 효과 -> Transaction 대기 시간을 최소화
0 : ( default)그룹 커밋의 효과가 중요
1 : 동시에 commit 이 발생하여 transaction 처리?
2 : 처리량이 commit 속도에 따라 제한 되는 경우 도움 ?
wal_debug 를 활성화 하면, XLogInsertRecord, XLogFlush 의 call 횟수를 확인할 수 있음.
WAL 데이터를 Disk 에 Writer 하는 함수는 XLogWrite and issue_xlog_fsync 존재
WAL 데이터를 동기화하는 데 소요되는 시간은, pg_stat_wal 내의 wal_write_time and wal_sync_time 에 기록
wal_sync_method 가 open_sync 또는 open_datasync 이면, XLogWrite는 WAL 데이터를 Disk 로 flush 하고 데이터 정합성을 보장하고, issue_xlog_fsync 는 어떠한 작업도 하지 않음
wal_sync_method 가 fdatasync , fsync , 또는 fsync_writethrough 가 되면, write opertaion이 WAL buffer 를 kernal cache로 이동하고 issue_xlog_fsync 는 kernal cache 내용을 Disk로 동기화 진행
XLogWrite Write 및 issue_xlog_fsync 가 WAL 데이터를 disk 로 동기화하는 횟수가, pg_stat_wal 에서 wal_write 및 wal_sync 값으로 저장
WAL Internal
WAL 는 rotation 하기 때문에, 관리자가 별도로 disk 관련하여 신경쓰지 않아도 됨
LSN 으로 어느 WAL 파일에 작성해야 하는지 (마지막 지점) 확인
WAL 파일은 Data directory 아래 pg_wal directory 에 segment file 로 저장되며, 16mb