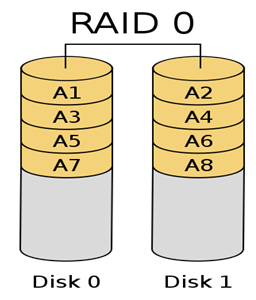
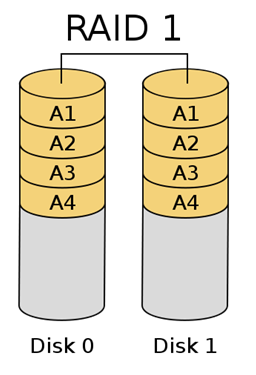
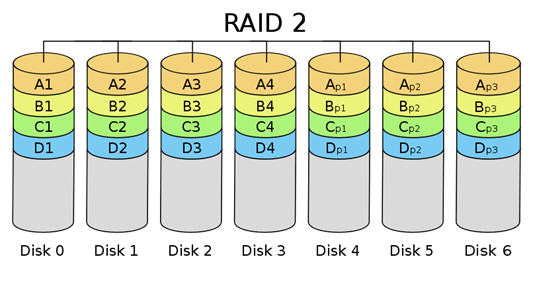
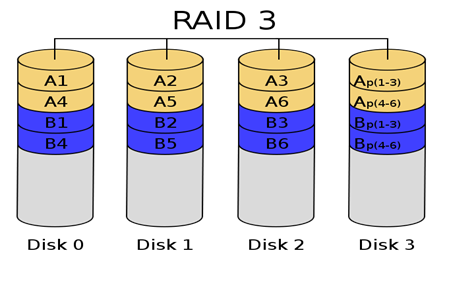
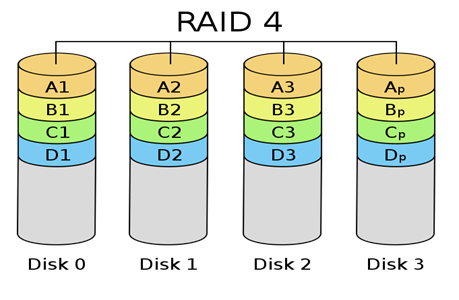
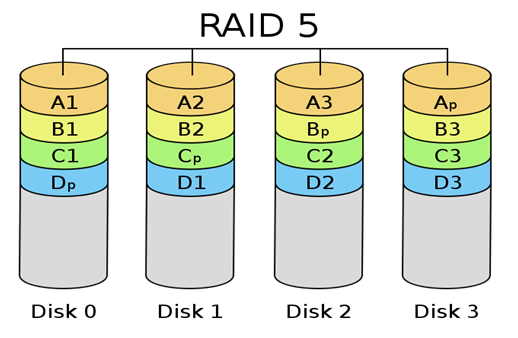
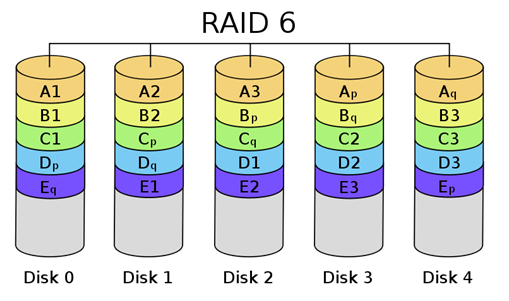
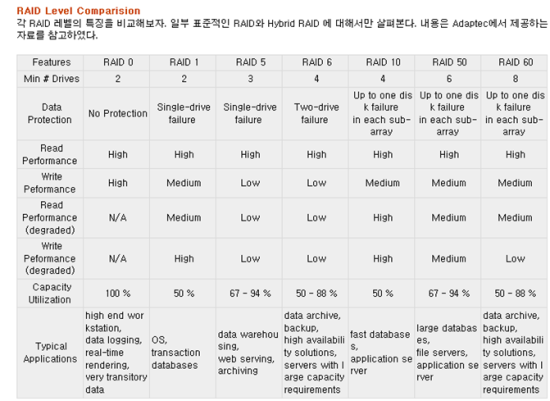
[출처] http://kin.naver.com/qna/detail.nhn?d1id=1&dirId=10302&docId=63819461&qb=cmF3IGRldmljZQ==&enc=utf8§ion=kin&rank=3&sort=0&spq=0&pid=fIe7Og331yosssEVpKlssv--169396&sid=S6RJEjE8pEsAACHkFto
흔히 유닉스에서 스토리지 디바이스를 억세스하는 방법에 따라
블록디바이스(/dev/dsk) 와 로(RAW)디바이스(/dev/rdsk) 로 구분을 합니다.
단어 그대로 이해를 한다면 블록디바이스에 블록은 파일시스템의 블록을 말하는 겁니다.
즉 로디바이스위에 파일시스템이 얹어 있다고 보면 됩니다.
OS 는 어플리케이션의 IO 요구에 따라 파일 시스템에서 읽어 오느냐 ,
로 디바이스(파일시스템 보다는 더 하위레벨)에서 읽어 오느냐가 억세스 방법에 의해서
차이가 있습니다.
로 디바이스는 파일시스템이 없기 때문에 당현히 파일, 디렉토리, 억세스컨트롤 등을
어플리케이션에서 직접 관리 해야 합니다.
로 디바이스를 데이타베이스에서 사용할 때 데이타 베이스는 자체적으로 블록과 익스텐트 등의
스토리지 관리 개념을 가지고 있기 때문에 OS레벨에서의 물리적인 데이타 파일 관리만 하면 됩니다.
(데이타 베이스에서 로디바이스를 사용하더라도 물리적인 디바이스(디스크)에 데이타 파일형태로 위치해야
하기 때문에 볼륨매니저 같은 가상 스토리지 개념이 필요합니다.)
일반적인 디스크는 I/O 다음과 같은 패스를 가집니다.
Application<->Library Buffer<->Operation System Cache<->File System/Volume Manager<->Device
그런데 로디바이스의 패스는 다음과 같습니다.
Application<->Device
흔히 DBMS 를 컨피그할때 데이타 파일의 위치를 놓고 RAW 와 파일시스템 비교를 많이 하게 됩니다.
나름대로 장단점이 있어 쉽게 판단 할수는 없지만 파일관리측면에선 파일시스템이 성능면에서는 로 디바이스가 낫습니다.
DBMS 시스템에서 파일시스템을 사용 할 경우 DBMS 의 가 자체 IO버퍼를 설정 하기 때문에
OS 의 파일시스템 캐시가 필요 없습니다. 이런 파일시스템의 단점을 보완하고자 솔라리스의 Direct I/O , 베리타스 파일시스템등
이 나오게 되었습니다. 이와 같은 더블 버퍼링 를 막음으로써 OS는 메모리 파일시스템 캐싱을 위한 메모리 매니지먼트가 필요없어지고,
DBMS 에서만 버퍼링을 하므로 메모리를 덜 소모하게 됩니다. 주소 변환을 할 필요가 없으니 캐시의 억세스 속도도 빨라지겠죠.
RAW의 장점을 하나더 말씀드리면 KAIO(kernal async IO) 입니다.
위의 IO패스에서 보듯이 로디바이스는 IO요구가 발생될때 유저라이브러리를 사용 하지 않고 커널 레벨에서 IO 가 이루어 지므로
명령이 단순해 져서 결과적으론 CPU를 덜 사용하게 됩니다.
--------------------------------------------------------------------------------------------------
[출처] http://boeok.tistory.com/entry/File-System-%EA%B3%BC-Raw-Device%EC%9D%98-%EC%B0%A8%EC%9D%B4
File system
- File system이란?
파일시스템(filesystem)이란 운영체제가 파티션이나 디스크에 파일들이 연속되게 하기 위해 사용하는 방법이고 자료구조이다. 즉, 파일들이 디스크상에서 구성되는 방식이다. 파일시스템이라는 말은 파일을 저장하는데 사용되는 파티션이나 디스크를 가리킬 때나, 파일 시스템의 형식을 가리킬 때 사용되기도 한다. file system은 mount란 단계를 거쳐서 특정 block device를 사용할 수 있게 해주는 것입니다.
- File system의 구조
partition | partition | partition |
Disk drive
Boot block | Super block | Inode list | Data block |
File system
• boot block : file system의 처음에 위치. operation system이 초기화되거나 부팅될 때, 필요한 bootstrap 코드를 포함하고 있다. 시스템이 부팅되기 위해서는 단지 하나의 부트 블록이 필요하며, 모든 시스템에는 부트 블록이 있어야 한다.
• super block : filesystem에 대한 모든 중요한 정보를 저장하는 곳이다. file system이 얼마나 큰지, 얼마나 많은 파일을 저장할 수 있는지, 자유 저장공간을 어디에서 찾아야 하는지 등의 다양한 정보를 포함하고 있다. 여기에 들어가는 정보는 파일시스템에 의존한다.
• inode list : 파일 시스템이라는 것은 inode(index node)라는 형태의 정보로 저장된다. inode는 항목(파일, 디렉토리, 심볼릭 링크) 자체의 이름을 제외하고는 다른 모든 파일시스템을 저장한다. 파일이름은 디렉토리에 저장되며 이는inode의 포인터로 이용된다. Inode list 는 inode들의 리스트이며, 관리자에 의해 그 크기가 변경될 수 있다. 파일 시스템의 모든 파일이나 디렉토리는 각기 단 하나의 inode에 의하여 표현된다. 리스트에서 한 inode는 root inode로 file system을 mount 시킨 이후에 접근 가능하게 된다.
• data block : 파일 데이터와 관리 데이터를 저장하고 있는 부분이다. 각각의 데이터 블록은 한번에, 단지 하나의 파일에만 할당될 수 있다.
Raw Device
- Raw Device란?
Raw device는 file system이 set up 되지 않은 disk drive이다. Raw Device는 데이터베이스와 같이 주로 자신들의 캐싱 시스템을 갖고 있는 경우에 서비스 프로그램에서 많이 사용한다. 운영체제의 캐싱 시스템은 일반적인 상황에서는 성능에 지대한 영향을 미치지만 데이터베이스 등에서는 이미 자신의 방식으로 캐싱을 하기 때문에 두번의 캐싱으로 인해 부하가 생길 수 있다. 그러므로 운영체제가 지원하는 부분을 사용하지 않게 하기 위해서 raw device를 사용한다.또한 두 대 이상의 machine과 이 machine들이 공유하고 있는 disk로 구성되는 OPS의 경우, shared disk를 os file system으로 구성하면 한쪽에서만 이를 볼 수 있고 동시에 access하는 것이 불가능하다. 그러므로 raw device를 사용해야 하며, raw device를 사용하면 os를 거치지 않으므로 보다 빠른 access를 기대할 수 있다.
• 장점
1. Raw Device는 os에 mount되지 않은 디스크이므로 os kernel에 의해 buffering이 되지 않고 user buffer와 device간에 직접 data가 전송되므로 disk I/O 성능이 향상되고 cpu overhead가 감소된다.
2. os file system의 overhead를 피할 수 있다.
3. os buffer size를 줄일 수 있다.
• 단점
1. setup 하기 어렵고 backup 절차가 file system 보다 복잡하다.
2. raw device와 os file을 혼합하여 사용할 경우 os file은 ulimit parameter의 size 보다 작아야 한다. 따라서 ulimit를 초과하는 table들은 raw device를 사용하여야 한다.
3. os는 cylinder 0을 보호하지 못하기 때문에 cylinder 0에서 시작하면 안된다.
- raw device 운영시 주의사항
² raw device는 ‘/dev’ directory 밑에 c type (character special file)으로 나타난다.
예>
crw-rw---- 1 oraerp01 dba 64 0x090001 May 15 14:07 rlvabmd01.dbf
crw-rw---- 1 oraerp01 dba 64 0x090002 May 15 14:07 rlvabmx01.dbf
crw-rw---- 1 oraerp01 dba 64 0x090003 May 15 14:07 rlvahld01.dbf
² logical volume 확인
lvdisplay –v lvpath
예> THVSD01:/dev/vgdbmst2> lvdisplay -v lvctrl1
² partitoin 개수 및 size 결정
oracle data file : device = 1 : 1
device size = oracle file size + a (a : 대략 1M 정도. header 정보 보관)
향후 DB가 늘어날 것을 감안하여 size 별 raw device를 미리 생성해둔다.
² file system의 file을 raw device 로 옮기는 방법 : dd if = file명 of = raw device명예>
dd bs=20480 if=/DBMS/orarac/oradata/RAC/rlvsystem01.dbf of=/dev/vgdbmsg1/rlvsystem01.dbf
dd bs=20480 if=/DBMS/orarac/oradata/RAC/rlvtemp01.tmf of=/dev/vgdbmsg1/rlvtemp01.tmf
dd bs=20480 if=/DBMS/orarac/oradata/RAC/rlvtools01.dbf of=/dev/vgdbmsg1/rlvtools01.dbf
² raw device를 file로 copy하는 방법 : dd if = raw device명 of = file명 예>
dd bs=20480 if=/dev/vgdbmsg1/rlvsystem01.dbf of=/DBMS/orarac/oradata/RAC/rlvsystem01.dbf
dd bs=20480 if=/dev/vgdbmsg1/rlvtemp01.tmf of=/DBMS/orarac/oradata/RAC/rlvtemp01.tmf
dd bs=20480 if=/dev/vgdbmsg1/rlvtools01.dbf of=/DBMS/orarac/oradata/RAC/rlvtools01.dbf