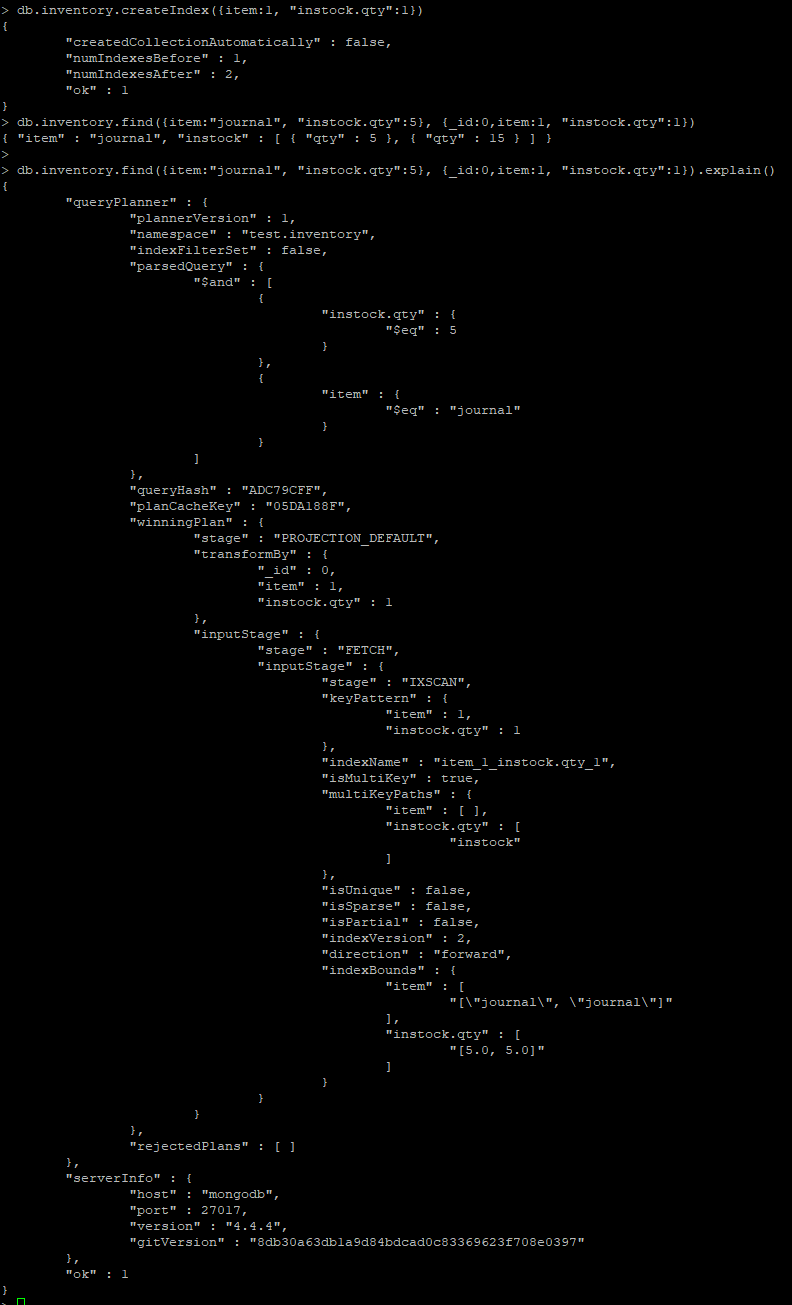
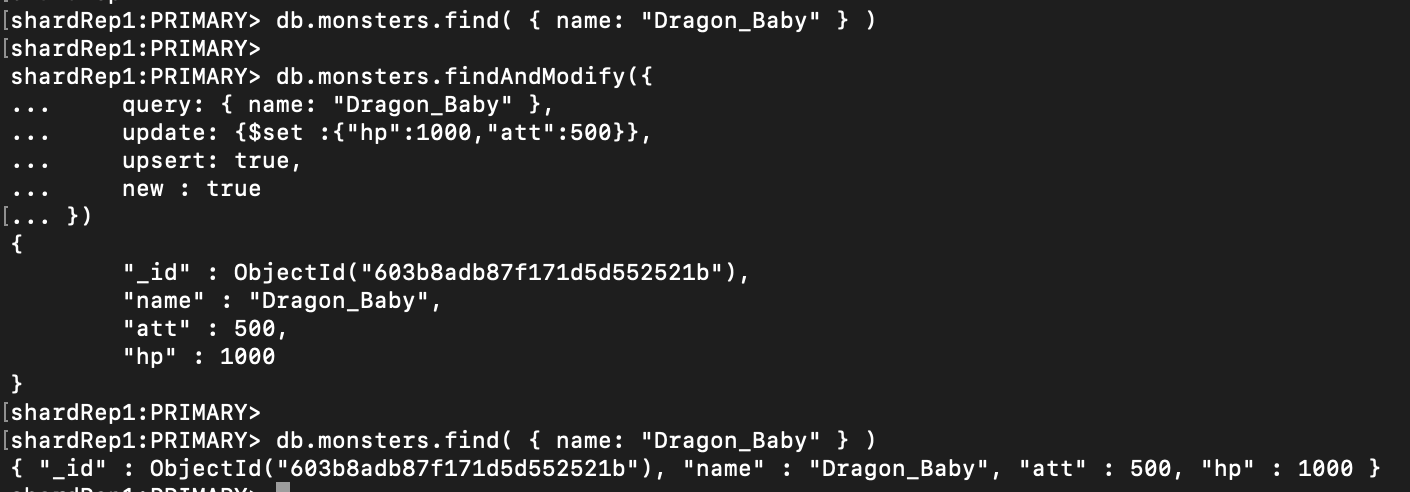
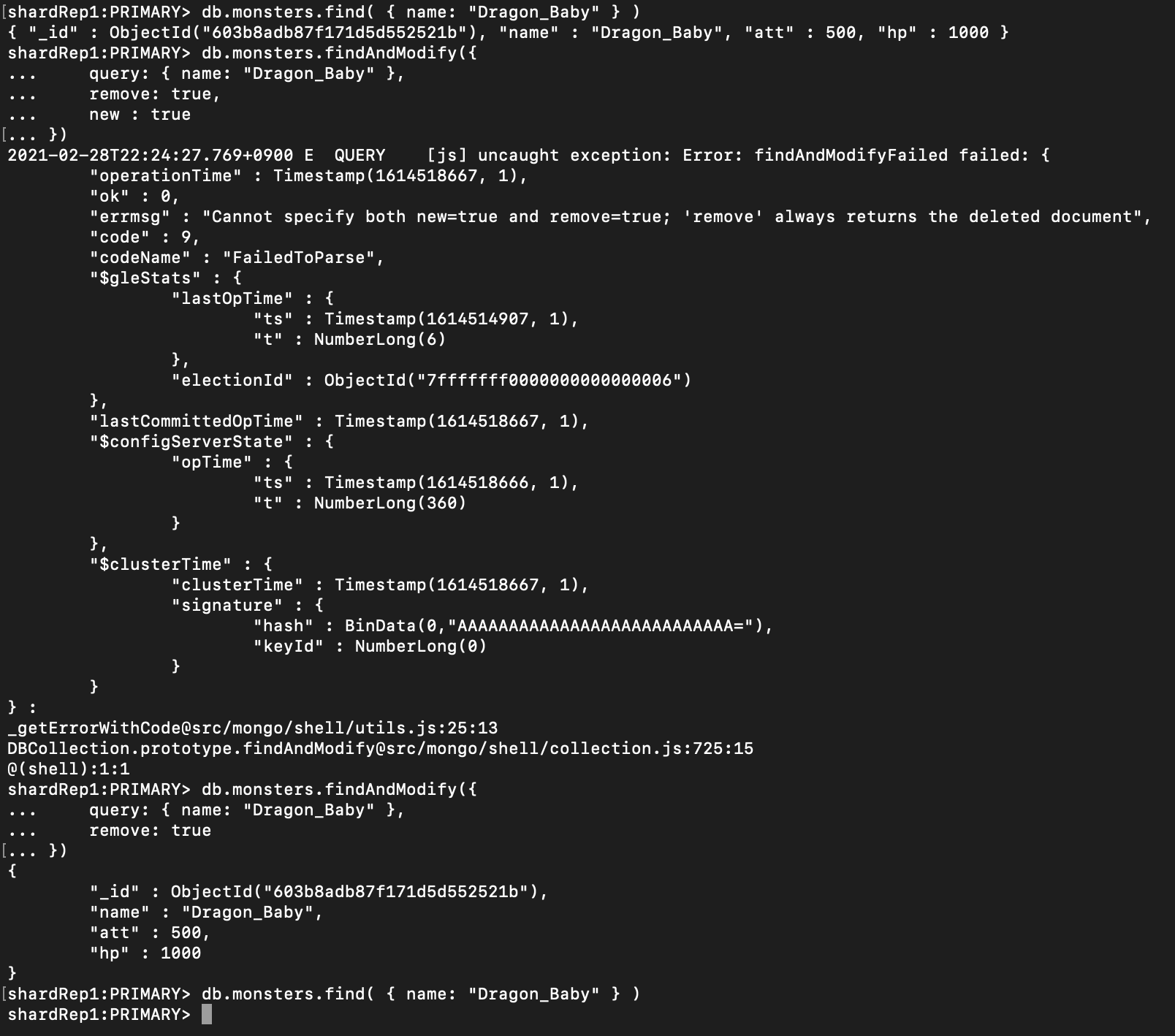
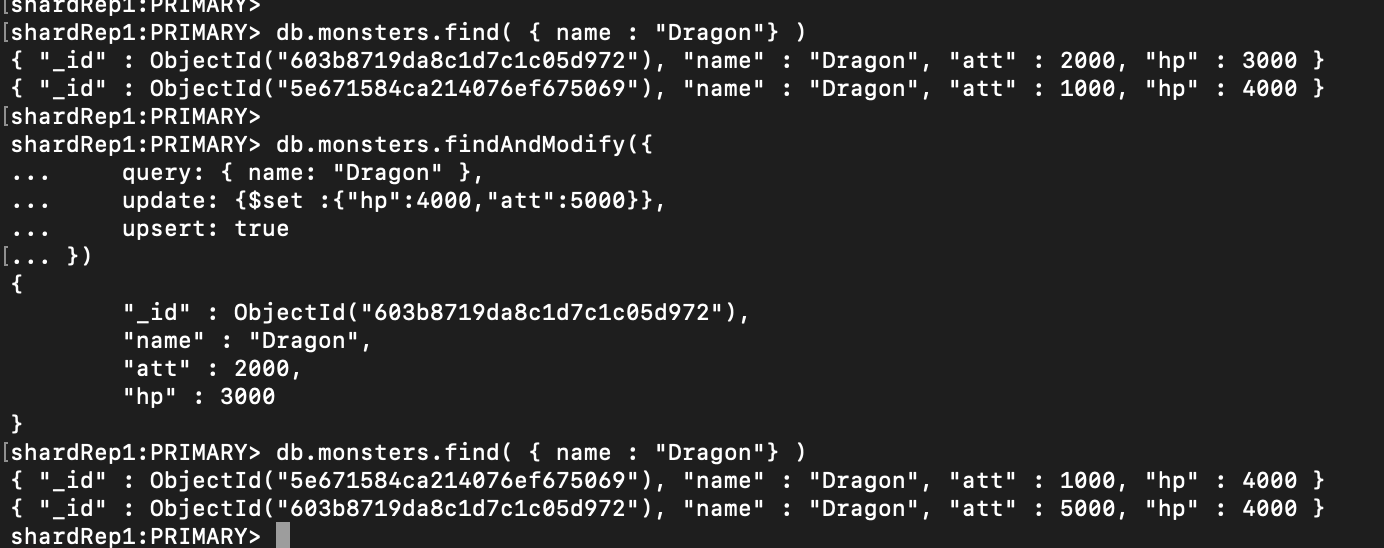
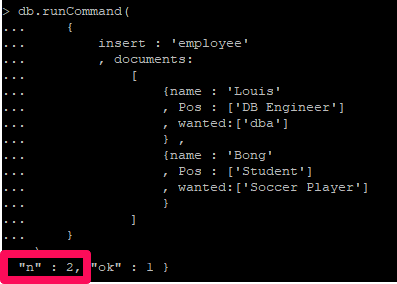
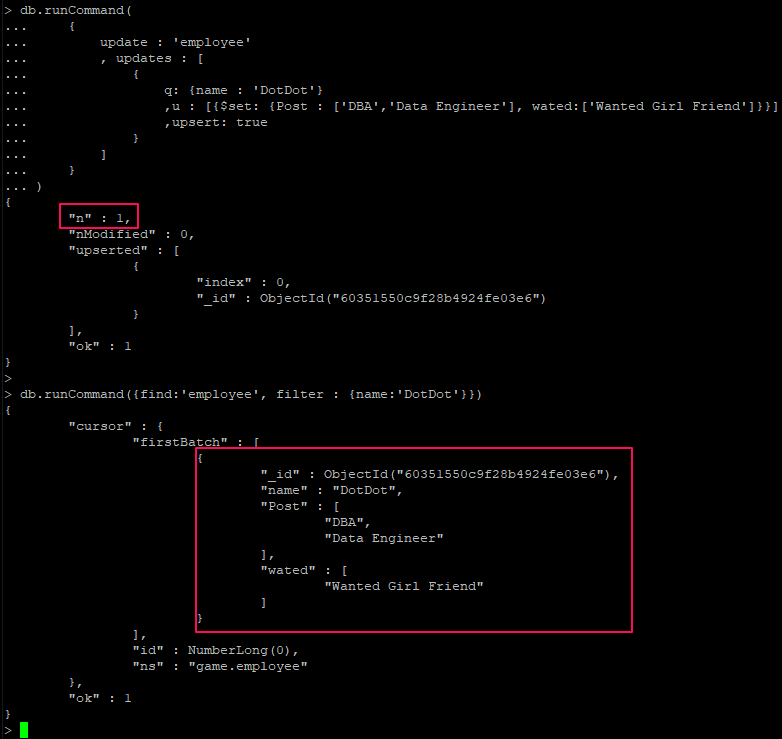
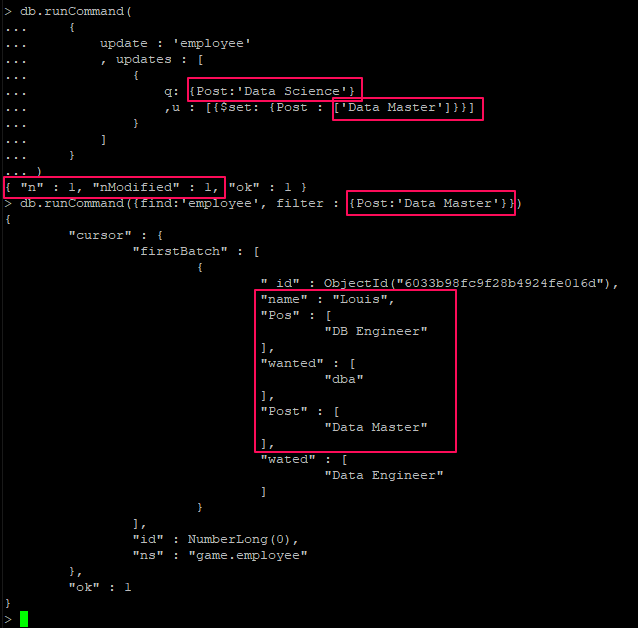
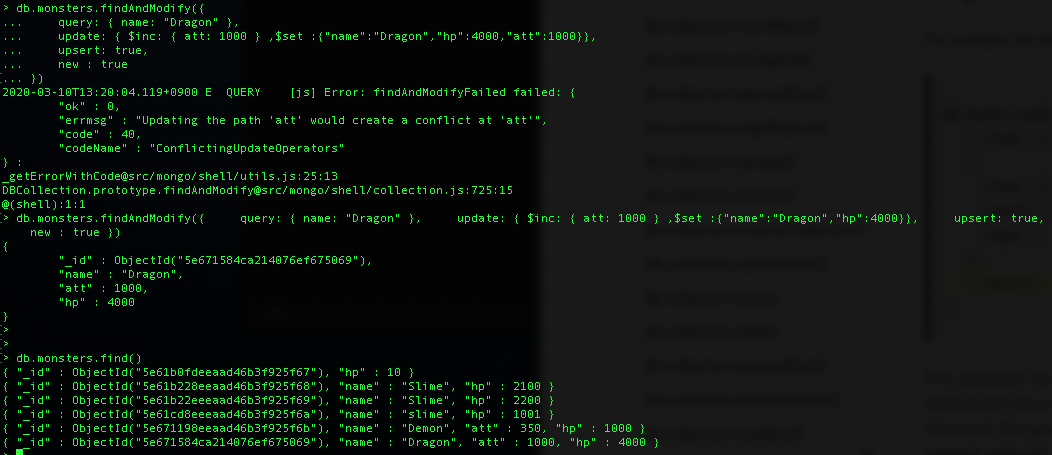
Multikey Index에서 배열 필드에 대해서는 Covered index 가 불가능(v3.6부터 non-array field들에 대해서는 사용 가능)
Covered Query
field 명시 방법
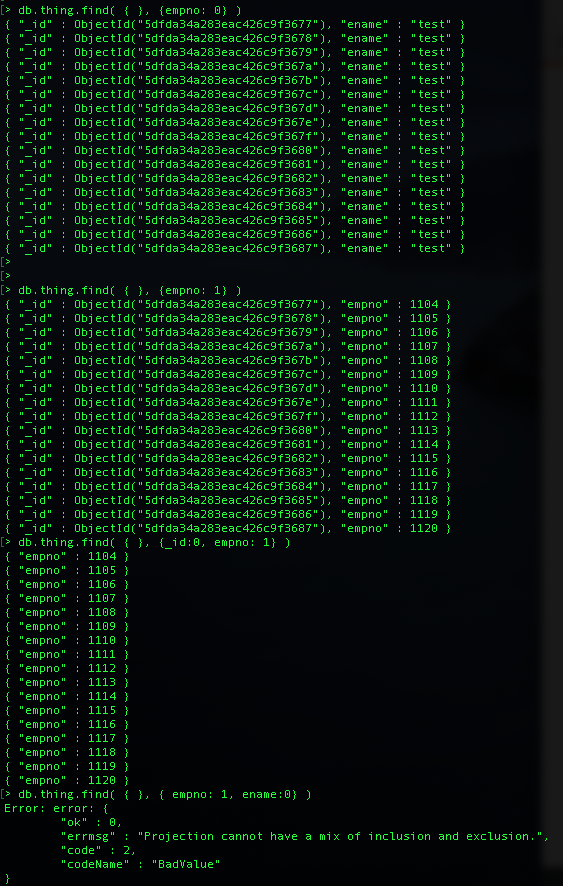
필드에 _id 여부는 항상 명시해야 함(_id를 쿼리 결과 내에서 표현하거나 표현하지 않는 것에 대해 명시를 반드시 해야 함)
_id에 대해서만 혼용 사용 가능하며, 다른 필드들에 대해서는 보여 주고 싶은 것에 대해서만 1로 명시, 0으로 명시하면 에러 발생
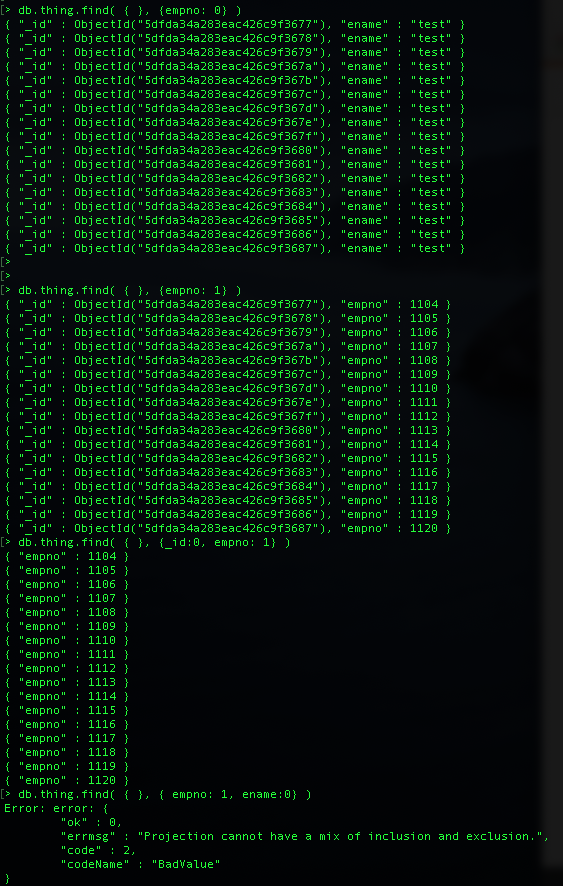
Ex ) > db.thing.find( { }, {_id:0, empno: 1} ) // empno만 표시하고, _id 및 다른 필드는 표시 안함. // 여기서 중요한건 _id는 항상 명시해 줘야 하며, 보고 싶은 필드만 1로 설정해서 표시 // 다른 필드의 경우 birth 필드가 있더라도 birth:0 으로 하면 에러 발생...왜???모르겠음
만약 empno만 빼고 다 보고자 하면 그때는 > db.thing.find( { }, {empno: 0} ) 이런 식으로 표시
보고 싶은 field가 있다면, field를 명시할 때 보겠다는 field 들만 명시를 하고,field 명시 여부를 혼용해서 명시하게 되면, 에러가 발생
반대로 보고 싶지 않은 field가 있다면 명시 안하겠다는 field 들만 명시를 해야 함
[Filed]
Covered Query Test
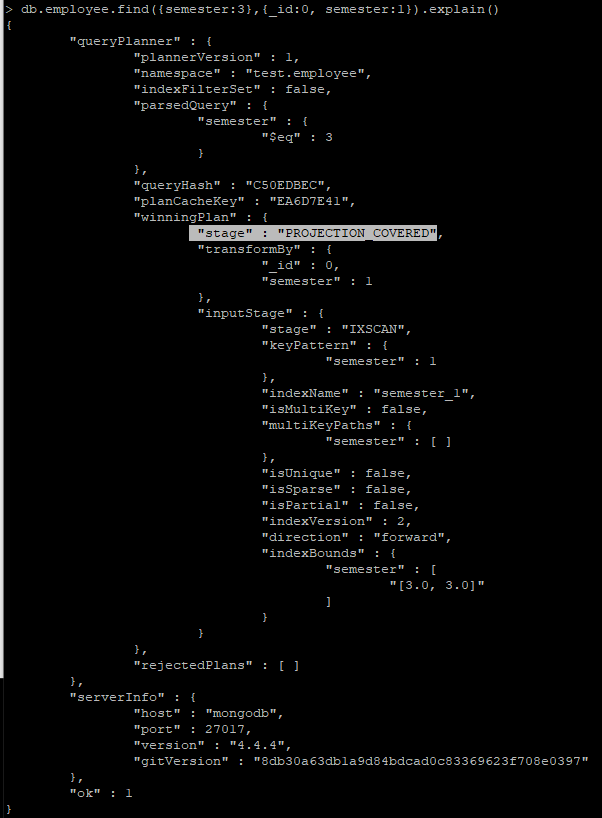
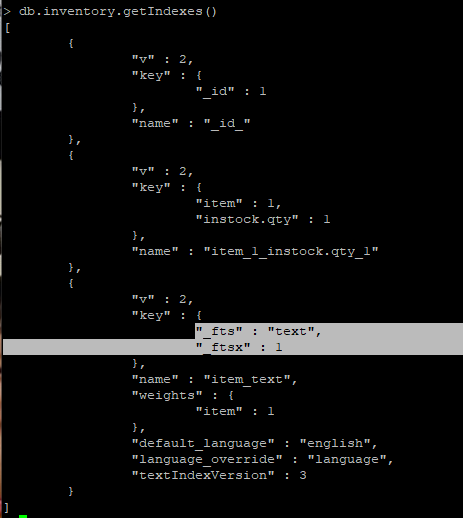
# semester 에 대한 Index 확인
> db.employee.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_"
},
{
"v" : 2,
"key" : {
"semester" : 1
},
"name" : "semester_1"
}
]
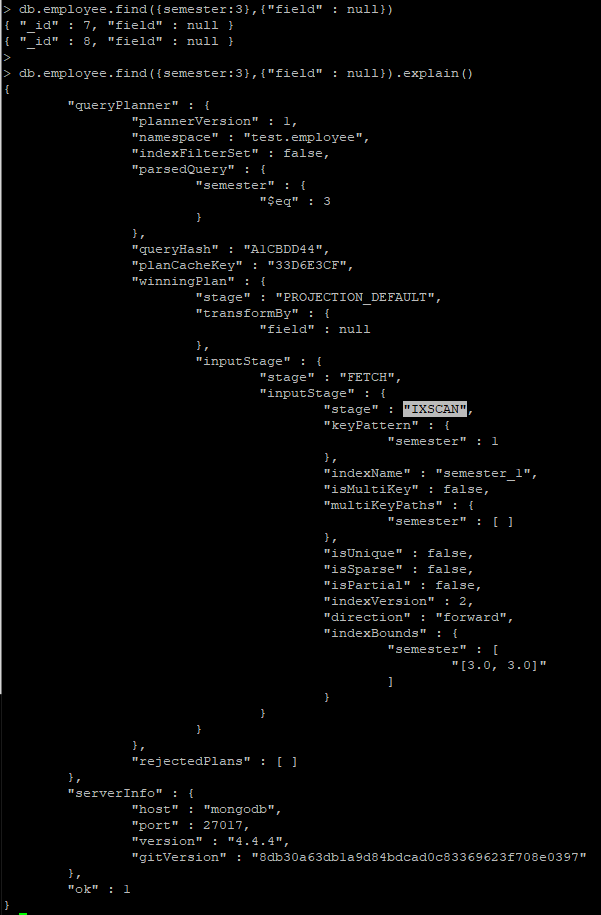
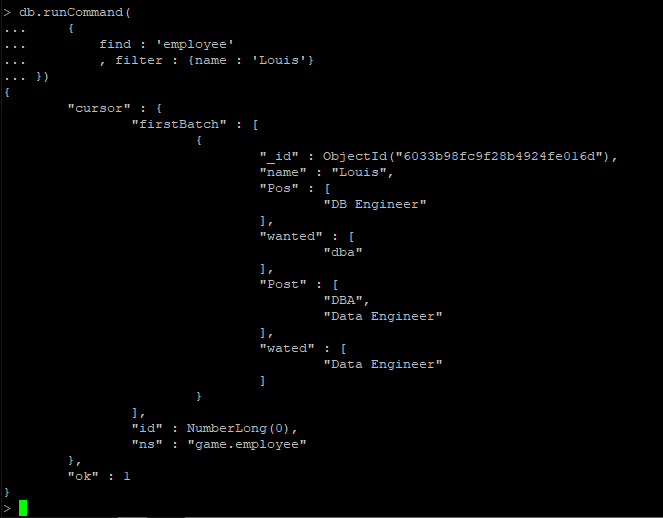
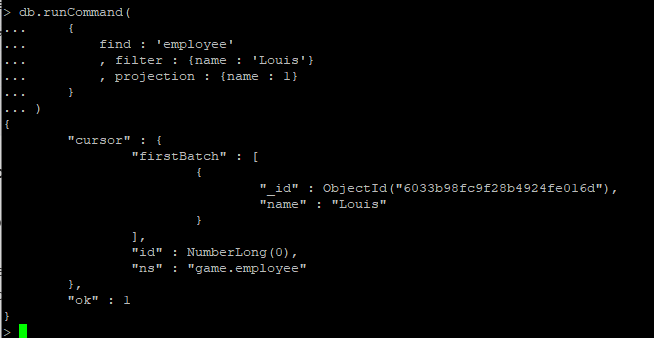
# _id 필드를 명시적으로 0 처리 하지 않으면, 자연스럽게 _id 필드도 같이 표시되기 때문에 명시적으로 _id 필드를 표시 안한다고 해야, Convered query 적용 여부를 확인 가능
> db.employee.find({semester:3},{_id:0, semester:1}).explain()
# 필드를 표시 안하게 되는 경우 _id 필드가 표현 되기에 covered query가 되지 않음
> db.employee.find({semester:3},{"field" : null}).explain()
# covered index 확인
# 필드를 표시 안 하게 되는 경우 _id 필드가 표현 되기에 covered query가 되지 않음 (단순 인덱스 스캔 - fetch 진행)
Universally unique identifier 의 약어로, 16-octet(128bit) 크기의 32개의 Hexa로 표시
OSF에서 표준화(개방 소프트웨어 재단(Open Software Foundation)-유닉스 운영 체제의 일부로 오픈 표준을 만들 목적으로 1984년의 미국 National Cooperative Research and Production Act 하에 1988년에 설립된 비영리 단체)
UUID를 구현하는데는 다양한 방식이 있는데, MAC address 나 HASH(md5, sha-1) 등을 이용한 방식이 유명
MAC address 자체가 unique 하기 때문에, 여기에 현재의 시간을 붙이는 방식으로 구현이 가능
# 일반적으로 사용하는 명령어는 command 에 작성하여 사용 가능
# Default
> db.runCommand(
{
명령어
}
)
# 관리 administrative 명령어의 경우 아래와 같이 사용 가능
> db.adminCommand( { <command> } )
Changes the minimum number of data-bearing members (i.e commit quorum), including the primary, that must vote to commit an in-progress index build before the primary marks those indexes as ready.
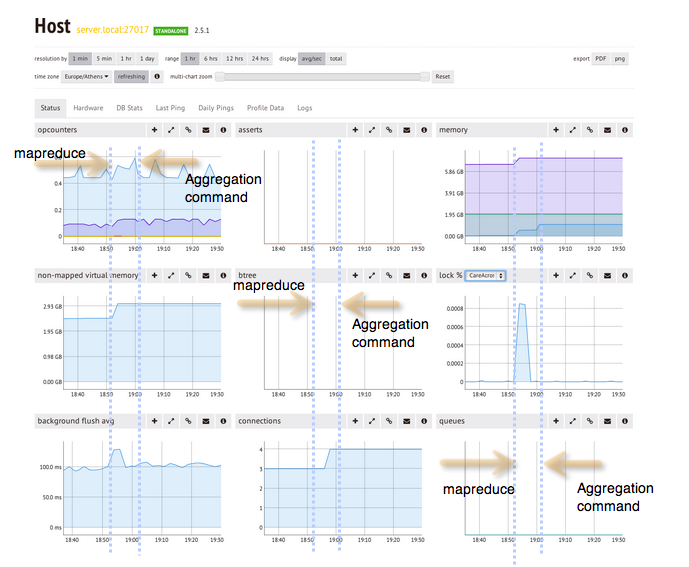
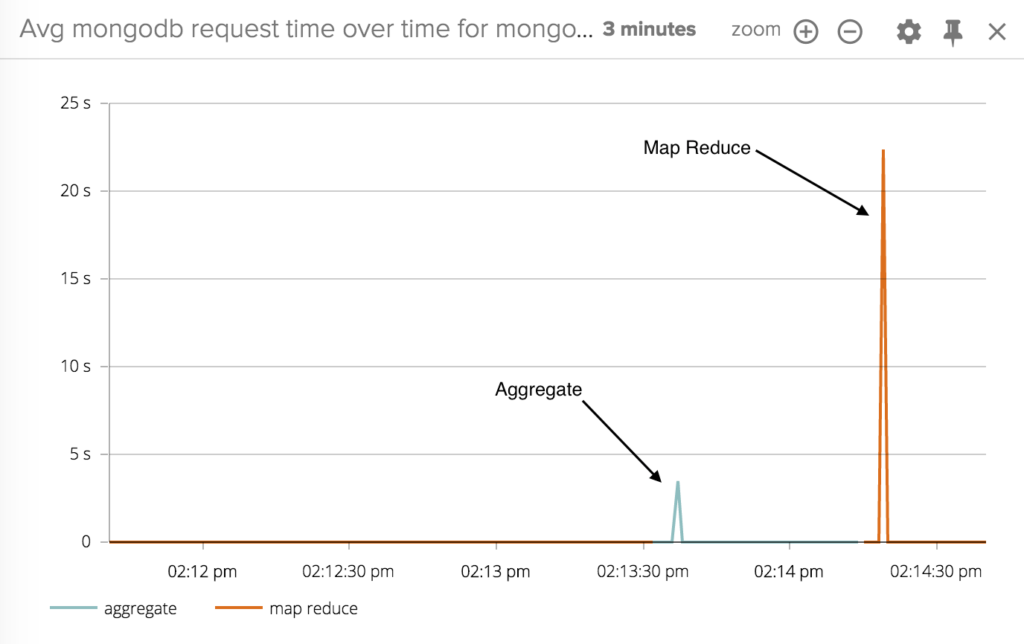
MongoDB의 Aggregate() 명령은 기본적으로 정렬을 위해서 100mb 메모리까지 사용 가능.
만약 그 이상의 데이터를 정렬해야 하는 경우라면 Aggregate() 명령은 실패-> 이 때 allowDiskUse 옵션을 true로 설정 시 Aggregate()처리가 디스크를 이용해 정렬 가능. 이 때 MongoDB 데이터 Directory 하의에 "_temp" Diretory 를 만들어 임시 가공용 데이터 파일을 저장
limit 와 batchSize 를 지정하지 않는 경우 batch는 한번 당 101개의 Document 결과를 리턴 하지만, Document 당 너무 많은 데이터가 있는 경우 batch 한번 당 1Mb 가 최대 size
limit 와 batchSize 를 지정하는 경우, 지정한 수만큼 리턴
큰 수로 셋팅하더라도 4Mb 이상의 데이터를 한번의 Batch로 가져올 수 없음.
인덱스 없이 데이터를 sort하는 경우 첫 번째 batch에 모든 데이터를 가져오지만, 최대 4 Mb 초과할 수 없음.
> // for문을 돌려서 간단한 데이터로 200개 document 를 등록한다.
> for (var i = 0; i < 200; i++) { db.foo.insert({i: i}); }
> var cursor = db.foo.find()
> // batchSize나 limit 값 지정없이 find 했으므로 기본 batch 크기인 101 documents
> cursor.objsLeftInBatch()
101
> // 한번에 모든 document들을 가져오기 위해 큰 limit 값을 셋팅하면 batchSize는 모든 document 수가 된다.
> var cursor = db.foo.find().limit(1000)
> cursor.objsLeftInBatch()
200
> // batchSize 가 limit 크기보다 작으면 batchSize가 우선한다.
> var cursor = db.foo.find().batchSize(10).limit(1000)
> cursor.objsLeftInBatch()
10
> // limit 가 batchSize 보다 작으면 limit 가 우선한다.
> var cursor = db.foo.find().batchSize(10).limit(5)
> cursor.objsLeftInBatch()
5
> // 각각 1MB 데이터로 10개의 document 를 등록한다.
> var megabyte = '';
> for (var i = 0; i < 1024 * 1024; i++) { megabyte += 'a'; }
> for (var i = 0; i < 10; i++) { db.bar.insert({s:megabyte}); }
> // limit나 batchSize를 지정하지 않았으므로 첫번째 batch는 1MB 에서 멈춘다.
> // 결국 1개씩 반복적으로 데이터를 가져오게됨
> var cursor = db.bar.find()
> cursor.objsLeftInBatch()
1
만약 empno만 빼고 다 보고자 하면 그때는 > db.thing.find( { }, {empno: 0} ) 이런식으로 표시
_id에 대해서만 혼용 사용 가능하며, 다른 필드들에 대해서는 1과 0을 혼용해서 표시 안됨
조건 검색 시 가급적 _id를 작성하며 Range 검색 시 기간을 지정하여 검색 추천
Ex) db.bios.find( {"_id":{"$gte":ObjectId("5dfaf5c00000000000000000", "$lte":ObjectId("5dfaf5c00000000000000000")}, {_id:0, name:1 , money:1}) (오늘 이전 모든 데이터 검색 or 오픈 이후 모든 날짜에 대해 검색 같은 전체 검색은 지양, 어제부터 일주일 전, 현재부터 하루 전 데이터 식으로 검색을 추천)
filed 명시 방법
> db.thing.find( { }, {empno: 1} )
// empno 를 표시하고, _id는 default로 표시, 단 그 외(ename) 은 표시 안함
> db.thing.find( { }, {empno: 0} )
// empno 만 표시를 안하고 나머지 ename , _id는 표시
> db.thing.find( { }, {_id:0, empno: 1} )
// empno만 표시하고, _id 및 다른 필드는 표시 안함.
// 여기서 중요한건 _id는 항상 명시해 줘야 하며, 보고 싶은 필드만 1로 설정해서 표시
// 다른 필드의 경우 ename이 있더라도 ename:0 으로 하면 에러 발생 >> 왜?????
> db.thing.find( { }, {empno: 1, ename:0} )
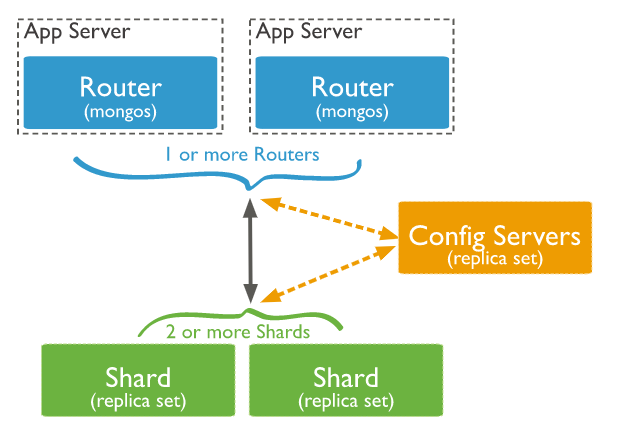
MongoS가 데이터를 쓰고/읽기 작업을 수행할 때 Config 서버는 MongoS를 통해 데이터를 동기화-수집 진행
MongoS
데이터를 Shard 서버로 분배해 주는 프로세스 (Router-Balancer)
Data를 분산하다 보면 작업의 일관성을 위하여 Lock을 사용
이때 Chunk Size를 적절하게 설계하지 못하면 Migration 때문에 성능 저하 현상이 발생 가능성
DB 사용량이 적은 시간대 Balancer를 동작시키고 그 외 시간에는 끄는 방법도 성능 향상의 방법
하나 이상의 프로세스가 활성화 가능(여러대의 MongoS를 운영 가능)
Application Server에서 실행 가능 (Application에서 직접적으로 접속하는 주체이며,독립적인 서버로 동작 가능하며, Application 서버 내에서도 API 형태로 실행 가능)
MongoS를 Application Server 서버 local 에 설치하는 것을 추천 (application server 가 별도의 라우터를 네트워크 공유 안하고, Local에서 직접 접근하기 때문에 효율성 증가. 별도의 서버를 구축 하지 않아서 서버 비용 절감. 단, 관리 포인트로 인한 문제점도 존재)
#mongodb 를 다운 및 압축 풀고 지정 경로에 저장
#필요 시 OS 유저 생성 (user add mongod)
$sudo groupadd mongod
$sudo useradd -g mongod mongod
$ wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-amazon2-4.2.6.tgz
$ tar -xvf mongodb-linux-x86_64-amazon2-4.2.6.tgz
$ mkdir /usr/local/mongodb
$ mv ./mongodb-linux-x86_64-amazon2-4.2.6/* /usr/local/mongodb
$ chown -R mongod:mongod /usr/local/mongodb
# data & log path 생성
$ mkdir -p /data/mongo/data
$ mkdir -p /data/mongo/log
$ chown -R mongod:mongod /data
#mongod 유저로 변경해서 아래내용 모두 진행
# add path
$ vi ~/.bash_profile
# .bash_profile
# path에 아래 내용 추가 수정 진행, 저장
mongodb=/usr/local/mongodb/bin
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$mongodb
# profile 적용
$ . ~/.bash_profile
# 존재 한다면 config 파일 백업
$ cp /etc/mongod.conf ~/mongod.conf.bak
공통 config 파일 설정 및 key 파일 생성 (Primary, Secondary 모두 동일하게 구성)
#Primary 내용
#key 파일 생성 (mongodb 간 접속을 진행 할 때 필요)
# 해당 key파일은 Secondary에 복사
$ sudo openssl rand -base64 756 > /usr/local/mongodb/mongo_repl.key
$ sudo chown mongod.mongod /usr/local/mongodb/mongo_repl.key
$ sudo chmod 600 /usr/local/mongodb/mongo_repl.key
# 아래 내용 복사
$ cat /usr/local/mongodb/mongo_repl.key
$ chmod 400 /usr/local/mongodb/mongo_repl.key
# Secondary DB 에서 위의 Primary DB에서 생성한 mongo_repl.key 의 내용을 복사 해서 동일한 위치에 붙여 넣고 저장 진행
# Secondary OS
# 복사한 Primary의 key 내용을 붙여 넣기 후 저장
$ vi /usr/local/mongodb/mongo_repl.key
$ chmod 400 /usr/local/mongodb/mongo_repl.key
Config 설정
# /etc/mongod.conf 수정
$ sudo touch /etc/mongod.conf
$ sudo chown mongod.mongod /etc/mongod.conf
$ vi /etc/mongod.conf
#기존 내용 삭제 및 해당 내용으로 대체
systemLog:
destination: file
path: /data/mongo/log/mongo.log
logAppend: true
logRotate: rename
storage:
engine: wiredTiger
directoryPerDB: true
wiredTiger:
engineConfig:
journalCompressor: snappy
collectionConfig:
blockCompressor: snappy
indexConfig:
prefixCompression: true
dbPath: /data/mongo/data
journal:
enabled: true
processManagement:
fork: true
#replication:
# replSetName: "replSet"
net:
bindIp: 0.0.0.0
port: 27017
#아래 내용은 replica 구성이 완료 되면 아래 주석을 풀어주도록 하자
#replication:
# replSetName: "replSet"
#security:
# authorization: enabled
# keyFile: /usr/local/mongodb/mongo_repl.key
참고로 systemlog 의 quiet 는 권장하지 않는다.
문제 발생 시 에러 내역 트랙킹 하기 힘들기 때문.
systemLog.quiet
Type: boolean
Run mongos or mongod in a quiet mode that attempts to limit the amount of output.
systemLog.quiet is not recommended for production systems as it may make tracking problems during particular connections much more difficult.
failIndexKeyTooLong : Index Key중 너무 큰게 있으면 저장되는 것을 fail 시켜라고 하는 파라미터
#Primary, Secondary 모두 진행
#서비스 등록
$ sudo vi /etc/systemd/system/mongodb.service
[Service]
User=mongod
ExecStart=/usr/local/mongodb/bin/mongod --config /etc/mongod.conf
# sudo에 mongod 유저 등록
$ visudo -f /etc/sudoers
#아래 내용 찾아 하단에 추가
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
mongod ALL=(ALL) ALL
MongoDB Startup
# Primary, Secondary , Arbiter 모두 진행
# Arbiter의 경우 이미 실행되어 있을 수 있으므로 mongodb가 Start가 되어있는지만 확인
# MongoDB 시작
$ sudo systemctl start mongodb
# MongoDB 상태 확인
$ ps -ef | grep mongod
MongoDB User 생성
# User 생성
# Primary에서만 진행
$ mongo
// 인증 DB가 admin
// root 계정 생성 및 게임서버 유저, bi 등에서 생성되는 유저 생성 진행
mongo> use admin
mongo> db.createUser(
{
user: "LKadmin",
pwd: "test!23",
roles:[
{ role: "root", db: "admin" }
]
}
)
> ObjectId("507c7f79bcf86cd7994f6c0e").getTimestamp()
ISODate("2012-10-15T21:26:17Z")
use database1 // database 선택
db.collection1.insert({ // collection.명령어 document
"name" : "Rouis.Kim" // field : value
, "age" : 37 // field : integer value
, "role" : "DBA" // field : string value
, "exp" : [{"Dev" : 5, "DBA" : 6}, {"Game": 3, "Ecommercail":2, "Enginner":3,"etc":3}] // field : Object value
, "loc" : [37.504997827623406, 127.02381255144938] // field : geomentry
, "etc" : ["2 daughters","프로이직러"] // field : array value
})
// document가 생성되지만, collection 이 존재하지 않으면 collection, database가 존재 하지않으면 database 까지 생성 됨
// schemaless (스키마 유연성)