반응형
Sharding의 정의
- 같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법
- Application Level 에서도 가능 (RDBMS 에서 Sharding) 하지만, Databas Level에서도 가능 (ex-MongoDB / Redis 등)
- Horizontal Partitioning (수평파티션) 이라고도 함
Sharding 적용
- 프로그래밍, 운영적인 복잡도는 증가하고 높아지는 것을 뜻함
- 가능하면 Sharding을 피하거나 지연시킬 수 있는 방법
- Sacle Up
- 하드스펙을 올리는 것
- Read 부하가 크면
- Replication 을 두어 Read 분산 처리
- Table의 특정 컬럼만 사용 빈도수가 높다면
- Vertically Partition(수직 파티션)을 진행
- Data를 Hot, Warm, Cold data로 분리하여 처리
- Memory DB를 활용
- 테이블의 데이터 건수를 줄이는 것

Sharding 방식
- Range Sharding (range based sharding)
- key (shard key) 값에 따라서 range 를 나눠서 데이터 를 분배하는 방식
- 비교적 간단하게 sharding이 가능
- 증설에 재정렬 비용이 들지 않음
- Shard key 의 선택이 중요
- Shard key에 따라 일부 데이터가 몰릴 수 있음(hotspots)
- 트래픽이 저조한 DB가 존재
- Hash Sharding (hash based sharding)
- key를 받아 해당 데이터를 hash 함수 결과로 분배
- Hotspot를 방지하고 균등하게 분배
- 재분배를 해야하는 경우(삭제 또는 추가) 전체 데이터를 다시 hash value를 이용하여 분배 (Migration 에 어려움)
- Directory Based Sharding
- shard내 어떤 데이터가 존재하는 지 추적할 수 있는 lookup table이 존재
- range based sharding 과 비슷하지만, 특별한 기준에 의해 shard를 나눈 것이라, 동적으로 shard를 구성 가능
- range나 hash 모두 정적인 반면, 해당 sharding은 유연성 있게 임의로 나누는 것이라 유연성을 갖춤
- 쿼리 할 때 모두 lookup table 를 참조하기 때문에 lookup table이 문제를 일으킬 소지를 보유
- lookup table이 hot spot 가능성
- lookup table이 손상되면 문제 발생
MongoDB Sharding
- 분산 처리를 통한 효율성 향상이 가장 큰 목적이므로 3대 이상의 샤드 서버로 구축을 권장(최소 2대)
- 싱글 노드 운영보다 최소 20~30% 추가 메모리 요구 (MongoS와 OpLog, Balancer 프로세스가 사용하게 될 추가 메모리 고려)
- 샤드 시스템에 구축되는 config 서버는 최소 3대 이상 활성화를 권장.
- Config 서버는 샤드 시스템 구축과 관련된 메타 데이터를 저장 관리하며 빠른 검색을 위한 인덱스 정보를 저장, 관리하고 있기 때문
- 샤드 서버와는 별도의 서버에 구축이 원칙
- Config 서버는 샤드 서버보다 저사양의 시스템으로 구축 가능

Config Server
- Config 서버는 샤딩 시스템의 필수 구조
- 최소 1대가 요구되며 장애로 인해 서비스가 중지되는 것을 피하기 위해 추가로 Config 서버 설정이 필요.(HA 구성 필요-PSS-필수)
- Config 서버는 각 샤드 서버에 데이터들이 어떻게 분산 저장되어 있는지에 대한 Meta Data가 저장 (Shard 정보를 저장 관리)
- Shard Meta 정보
- MongoS가 처리하는 Chunk 단위로 된 chunk 리스트와 chunk들을의 range 정보를 보유
- 분산 Lock
- MongoS들 간의 config 서버와의 데이터 통신 동기화를 위해 도입
- 샤딩을 수행할 연산들에 대해 분산 락을 사용
- 여러개의 mongos가 동시에 동일한 chunk에 대한 작업을 시도하는 등의 이슈를 방지하기 위함
- 작업을 수행하기 전 config server의 locks collection 의 lock을 획득 후에만 작업 가능
repl_conf:PRIMARY> db.locks.find()
{ "_id" : "config", "state" : 0, "process" : "ConfigServer", "ts" : ObjectId("5d6b7f15a9f5ecd49052a36f"), "when" : ISODate("2019-09-01T08:19:33.165Z"), "who" : "ConfigServer:conn164", "why" : "createCollection" }
{ "_id" : "config.system.sessions", "state" : 0, "process" : "ConfigServer", "ts" : ObjectId("5d6b7f15a9f5ecd49052a376"), "when" : ISODate("2019-09-01T08:19:33.172Z"), "who" : "ConfigServer:conn164", "why" : "createCollection" }
{ "_id" : "testdb", "state" : 0, "process" : "ConfigServer", "ts" : ObjectId("5d62889d3ed72a6b6729a5ca"), "when" : ISODate("2019-08-25T13:09:49.728Z"), "who" : "ConfigServer:conn24", "why" : "shardCollection" }
{ "_id" : "testdb.testCollection2", "state" : 0, "process" : "ConfigServer", "ts" : ObjectId("5d62889d3ed72a6b6729a5d1"), "when" : ISODate("2019-08-25T13:09:49.738Z"), "who" : "ConfigServer:conn24", "why" : "shardCollection" }
{ "_id" : "test.testCollection2", "state" : 0, "process" : "ConfigServer", "ts" : ObjectId("5d6288ab3ed72a6b6729a65a"), "when" : ISODate("2019-08-25T13:10:03.834Z"), "who" : "ConfigServer:conn24", "why" : "shardCollection" }
- Lock 역할
- 밸런서(balancer)의 연산
- Collection 의 분할(split)
- Collection 이관(migration)

- LockPinger : 해당 쓰레드는 30초 주기로 config 서버와 통신
- 밸런서와 연관이 있으며, 읽기,쓰기 발생 시 config 서버에 해당 lock 을 취득하는 과정을 관장하는 역할
- 자세한 내용은 http://mongodb.citsoft.net/?page_id=256 을 참조 (lockpinger 관련한 에러 버그들이 존재했지만, 현재는 더이상 정보를 찾기가 힘드네요)
- lockpinger bug : https://jira.mongodb.org/browse/SERVER-17812
- 복제 집합 정보 : MongoS가 관리, 접속해야 하는 Mongo Shard 정보
- MongoS가 데이터를 쓰고/읽기 작업을 수행할 때 Config 서버는 MongoS를 통해 데이터를 동기화-수집 진행
MongoS
- 데이터를 Shard 서버로 분배해 주는 프로세스 (Router-Balancer)
- Data를 분산하다 보면 작업의 일관성을 위하여 Lock을 사용
- 이때 Chunk Size를 적절하게 설계하지 못하면 Migration 때문에 성능 저하 현상이 발생 가능성
- DB 사용량이 적은 시간대 Balancer를 동작시키고 그 외 시간에는 끄는 방법도 성능 향상의 방법
- 하나 이상의 프로세스가 활성화 가능(여러대의 MongoS를 운영 가능)
- Application Server에서 실행 가능 (Application에서 직접적으로 접속하는 주체이며,독립적인 서버로 동작 가능하며, Application 서버 내에서도 API 형태로 실행 가능)
- MongoS를 Application Server 서버 local 에 설치하는 것을 추천
(application server 가 별도의 라우터를 네트워크 공유 안하고, Local에서 직접 접근하기 때문에 효율성 증가. 별도의 서버를 구축 하지 않아서 서버 비용 절감. 단, 관리 포인트로 인한 문제점도 존재)
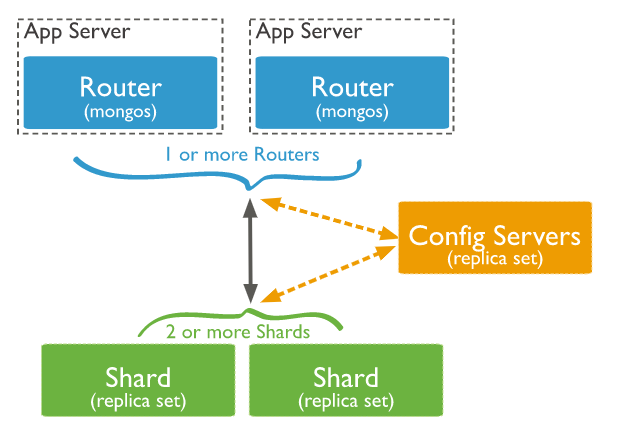
- Config 서버로부터 Meta-Data를 Caching
- read, write 작업시 해당 샤드를 찾을 수 있도록 캐쉬할 수 있는 기능을 제공
root@7d536b10b886:/# mongos --configdb config-replica-set/mongo1:27019,mongo2:27019 --bind_ip 0.0.0.0
- MongoS가 실행될 때 Config 서버를 등록
- Config 서버와 연결되면 샤딩 정책을 포함한 메타 정보를 연결된 모든 Config 서버에 전송
- MongoS는 Config Server 와 연결하게 되는데, Config Server가 여러 대인 경우 여러 대 중 하나라도 연결이 안되면 MongoS 는 연결 실패로 MongoS가 실행되지 않음
- MongoS 내에서는 데이터를 저장하지 않으며, 다른 MongoS간 연결이 없기 때문에 데이터 동기화를 위해 Config 서버를 이용
- MongoS 의 쿼리 클러스터 라우팅 방법
- 쿼리를 보내야 하는 샤드 리스트를 결정
- 대상되는 샤드에 커서를 설정
- Target Shard에 보낸 결과를 받아 데이터를 병합하고 해당 결과를 Client로 Return
- Mongo3.6에서는, 집계 쿼리의 경우 각 Shard에서 작업하는 것이 아닌, Mongos에서 결과를 받아 merge 후 작업하여 리턴하는 형태로 변경
- MongoS에서 Pipline을 운영할 수 없는 2가지 경우
- 분할 파이프라인의 병합 부분에 Primary shard 에서 동작해야하는 부분이 포함되어 있는 경우
- $lookup 집계가 실행중인 Shard Collection 과 동일한 Database 내에 있는 unshared collection과 진행 된다면, 병합은 Primary shard에서 실행해야 함
- 분할 파이프라인의 $group과 같은 Temporary data를 Disk에 기록해야 하는 경우가 포함된 경우, 또한 Client는 allowDiskUse를 True 지정했을 경우 Mongos를 사용할 수 없음
- 이런 경우, Merged 파이프라인은 Primary shard에서 하지 않고, 병합 대상인 샤드들 중 무작위로 선택된 샤드에서 실행
- Shard cluster 에서 Aggregation 쿼리가 어떻게 동작하고 싶은지 알고 싶으면, explain:true 로 설정하여 aggregation을 실행하여 확인 가능
- mergeType은 병합 단계에서 ("primaryShard", "anyShard", or "mongos") 로 보여주며, 분할 파이프라인은 개별샤드에서 실행된 작업을 리턴.
- https://docs.mongodb.com/manual/core/sharded-cluster-query-router/ 참고
Chunk
- collection을 여러 조각으로 파티션하고 각 조각을 여러 샤드 서버에 분산해서 저장하는데, 이 데이터 조각을 Chunk라고 함
- chunk는 각 샤드서버에 균등하게 저장되어야 좋은 성능을 낼 수 있음
- 균등하게 저장하기 위해 큰 청크를 작은 청크로 Split 하고 청크가 많은 샤드에서는 적은 샤드로 Chunk Migration 을 수행
- 청크 사이즈는 Default 64Mb 이며 size를 변경도 가능 (또는 100,000 row)
- Chunk size 변경 시 유의사항
- Chunk size를 작게하면 빈번한 마이그레이션이 동작하여 성능은 저하가 발생할 수 있으나, 데이터를 고르게 분배할 수 있는 효과를 볼 수 있다. (추가로 mongos에서 추가 비용이 발생)
- 청크 사이즈를 크게하면 마이그레이션 빈도는 줄어들어 네트워크나 mongos 에서 오버헤드 측면에서 효율적.그러나 잠재적으로 분포의 불균형이 발생 가능성
- 청크 사이즈는 마이그레이션할 청크 내 document 수와 비례(청크가 클수록 저장되는 document 수가 증가)
- 청크 사이즈는 기존 Collection을 분할할 때 최대 컬렉션 크기에 따라 영향. 샤딩 이후 청크 사이즈는 컬렉션 크기에 영향 없음
- Chunk Split
- 샤드 내 Chunk의 사이즈가 너무 커지는 것을 막기 위해 split 이 발생
- 청크가 지정된 청크 사이즈를 초과하거나, 청크내의 문서 수가 마이그레이션할 청크당 최대 문서 수를 초과할 경우 발생
- 이 때 split는 샤드 키 값을 기준으로 진행
- Insert 또는 update 시 split 이 발생
- split 이 발생하면 메타 데이터 변경이 발생하며, 데이터의 균등함을 가져온다
- Split 을 한다고 해도 청크가 샤드에 고르게 분포되지 않을 수 있음
- 이때 밸런서가 여러 샤드에 존재하는 청크를 재분배
- 클러스터 밸런서 참고
- Chunk Migration
- 여러 Shard 로 나누어진 청크를 샤드간 균등하게 분배하기 위하여 Migration 을 진행
- Balance 프로세스가 moveChunk 명령을 Source 샤드로 명령(Chunk Migration이 필요한 Shard=Source Shard)
- Source Shard는 moveChunk 명령으로 이동 시작
- 이동하는 Chunk는 라우팅 되어 동작하며, 경로에 대한 내역은 Source Shard에 저장(수신에 대한 내역)
- Target Shard는 해당 Chunk 관련한 Index를 생성(build)
- Target Shard는 Chunk 내의 Document 요청을 하고, 해당 데이터 사본을 수신 시작
- Chunk에서 최종(원본) Docuemnt를 수신한 후 Migration 간 변경된 내역이 있는지 확인하기 위하여 다시 한번 Target Shard는 동기화 프로세스를 시작
- 완전히 동기화가 완료되면, Config Server에 연결하여 Cluster Meta 데이터를 청크의 새 위치로 업데이트 진행(mongoS가 관여 하지 않을까....의견)
- Source Shard가 Meta 정보를 업데이트를 완료하고 Chunk에 열린 커서가 없으면 Source Shard는 Migration 대상을 삭제 진행
- 샤드에서 여러 청크를 마이그레이션 하기 위해서는 밸런서는 한 번에 하나씩 청크를 마이그레이션 진행
- 3.4에서부터는 병렬 청크 마이그레이션을 수행 가능. 단, 샤드가 한 번에 최대 하나만 참여하지만, 샤드가 n 개인 여러개의 샤딩된 클러스터의 경우 최대 샤드 n개/2 만큼 동시 Migration을 진행 가능
- 클러스터 내 Chunk Migration은 한번만 가능했지만, 3.4부터는 Cluster 내 최대 n/2 개의 Chunk Migration은 가능(단 하나의 샤드당 하나의 Chunk Migration만 가능)
- 하지만, 밸런서는 청크를 이동 후 이동한 청크를 삭제에 대해서(삭제단계)는 기다리지 않고 다음 마이그레이션 진행 (비동기식 청크 마이그레이션 삭제)
- 이로 인해 삭제 단계가 오래 소요 되는 경우도 발생
- MongoDB 4.4 에서는 삭제 단계에서 장애 조치가 발생하는 경우
- 기존에는 삭제 단계에서 장애 발생 시 삭제되어야 하는 청크가 삭제가 안되었지만, 4.4 버전 에서는 장애 조치 이후나 재시작 후에도 정리가 진행
- https://docs.mongodb.com/manual/core/sharding-balancer-administration/#sharding-migration-thresholds 참고
- attemptToBalanceJumboChunks 라는 밸런서 설정을 하면, 마이그레이션 하기 너무 큰 청크는 밸런서가 이동 시키지 않음
- Migration 조건
- 수동
- 대량 Insert 중 데이터를 배포해야 하는 경우 제한적으로 사용
- 수동 마이그레이션 참조
- 자동
- 밸런서 프로세스가 Collection 내 Chunk들이 파편화가 발생하여 고르게 분포 되지 않았다고 판단 될 때 Chunk를 이동 시킴
- 측정 임계값
- 하나의 샤드 서번에 8개의 Chunk가 발생하면 다른 서버로 Migration이 발생하는데 20개 미만의 Chunk가 발생하면 평균 2번 정도의 Migration 이 발생
- Migration이 빈번하게 발생하면 Chunk를 이동하기 위한 작업이 수시로 발생하기 때문에 성능 지연현상을 발생 시킬 수 있음
- 적절한 빈도의 Migration이 발생되기 위해서는 적절한 Chunk Size를 할당이 필요
|
Chunk 수 |
Chunk Migration 수 |
|
1 ~20개 미만 |
2 |
|
21 ~ 80 개 미만 |
4 |
|
80개 이상 |
8 |
Sharded Cluster Balancer
https://docs.mongodb.com/manual/core/sharding-balancer-administration/#sharding-internals-balancing
- 각 Shard의 Chunk 수를 모니터링하는 백그라운드 프로세스
- 샤드의 청크 수가 Migration 임계치 값에 도달 하면 밸런서가 샤드간에 Chunk를 자동으로 Migration하고 샤드 당 동일한 수의 청크를 유지
- 샤드된 컬렉션의 청크를 모든 샤드 컬렉션에 균등하게 재분배하는 역할(밸러서는 Default로 enable)
- 샤드간 청크가 균등하게 유지될 때까지 밸런서가 동작 (Migration 는 위의 Chunk Migration 동작을 참고)
- 밸런싱 절차는 사용자 및 어플리케이션 계층에서 투명하게 동작하지만, Migration이 진행되는 동안에는 부하가 발생
- 밸런서는 Config server Replica set에서 Primary에서 동작
- 유지보수를 위해 밸런서를 비활성화도 가능하며 수행 시간을 설정도 가능
- balancing 작업이 02:00 에 자동으로 수행
#Config 서버에서 동작을 확인 가능
repl_conf:PRIMARY> db.settings.update (
... {_id:"balancer"},
... {$set : {activeWindow: {start: "02:00", stop : "06:00" } } },
... {upsert : true } )
WriteResult({ "nMatched" : 0, "nUpserted" : 1, "nModified" : 0, "_id" : "balanver" })
repl_conf:PRIMARY> db.settings.find()
{ "_id" : "chunksize", "value" : 64 }
{ "_id" : "balancer", "stopped" : false }
{ "_id" : "autosplit", "enabled" : true }
{ "_id" : "balanver", "activeWindow" : { "start" : "02:00", "stop" : "06:00" } }- 샤드 추가 및 제거
- 샤드를 추가하게 되면 새로운 샤드에는 Chunk가 없기 때문에 불균형이 발생
- 클러스터에서 샤드를 제거하면 상주하는 청크가 클러스터 전체로 재분배가 일어나므로 샤드 추가와 같이 불균형이 발생
- 샤드를 추가하거나 삭제 모두 마이그레이션 하기 시작하면 시간이 소요
- 효율적인 방안은 좀 더 조사가 필요
Sharding System 주의점
- 하나의 Shard 서버에 데이터가 집중되고 균등 분산이 안 되는 경우
- Shard Key로 설정된 필드의 Cardinality가 낮은 경우에 Chunk Size는 반드시 64Mb 단위로 분할되는 것이 아님
- 때로는 64Mb보다 훨씬 큰 크기의 Chunk 크기로 생성되기도 함
- Default로 8개 정도의 Chunk가 발생하면 Migration이 발생하기 때문에 다른 서버로 Chunk를 이동하는 횟수는 줄어들게 되고 자연스럽게 하나의 샤드 서버에 만 데이터 집중되는 현상 발생
- 적절한 Shard Key를 선택하지 못한 경우 발생하는 문제점(Shard Key의 중요성)
- 혹여나 균등 분산이 안된다고 판단되면 Chunk Size를 줄이는 것을 추천(Migration 빈도수가 높아 져 균등하게 분활은 되나 성능 저하 발생)
- 특정 Shard 서버에 IO 트래픽이 증가하는 경우
- MongoDB의 샤드 서버는 동일한 Shard Key를 가진 데이터들을 같은 샤드 서버에 저장하기 위해 Split 과 Migration 수행
- Shard 서버의 IO 트래픽이 증가하는 이유는 너무 낮은 Cardinality 를 가진 Field를 설정 때문
- 데이터가 집중적으로 저장되어 있는 Chunk를 Hot Chunk라고 하며, 특정 서버에 집중되어 있을 때 상대적으로 서버 IO 트래픽이 증가
- 샤드 클러스터의 밸런스가 균등하지 않는 경우
- 데이터를 입력할 때 로드 밸런싱이 적절하게 수행되었지만 사용자의 필요에 따라 특정 서버의 데이터를 삭제 또는 다른 저장 공간으로 이동했다면 Balancer가 깨지게 됨
- Shard key 의 낮은 Cadinality
- 하나의 Collection에 대량의 Insert 되는 것 보다 분산 저장되는 속도가 늦는 경우 밸런스 불균형 발생
- Insert 되는 속도에 비해 Chunk Migration이 빈약한 네트워크 대역폭으로 인해 빠르게 이동되지 못하는 경우 발생
- 하루 일과 중 Peak 시간에 빈번한 Migration이 발생하게 되면 시스템 자원의 효율성이 떨어지게 되어 성능 지연 발생
- 피크 시간에 Chunk Migration을 중지하고 유휴 시간에 작업 될 수 있도록 Balance 설정
- 과도한 Chunk Migration이 클러스트 동작을 멈추는 경우
- 빈번한 Chunk Migration이 일시적으로 Cluster 서버 전체의 성능 지연 문제를 유발
- 빈번한 Migration 회수를 줄일 수 없다면 유휴 시간에 작업 될 수 있도록 Balance 설정
- 불필요하게 큰 Chunk Size는 네트워크 트래픽을 증가시키고 시스템 자원의 효율성을 저하 시키는 원인이 될 수 있으므로 Chunk size를 줄이는 것 고려
- Shard 서버의 밸런싱이 적절하지 않다는 것은 Shard 서버의 수가 처리하려는 데이터 발생 양에 비해 부족하기 때문이므로 샤드 서버 대수 증설 고려
- 쓰기 성능이 지연되고 빠른 검색이 안 되는 경우
- 초당 몇 만 건 이상의 데이터들이 동시에 저장되기 위해 Collection의 크기가 중요
- 하나의 Collection은 여러개의 익스텐트 구조로 생성되는데, 익스텐트 사이즈가 작게 생성되어 있으면 잦은 익스텐트 할당으로 인해 불필요한 대기 시간이 발생
- 충분한 익스텐트 크기로 생성(createCollection 을 이용하여 Collection을 명시적으로 생성하면서 size를 조정 가능)
- 빠른 쓰기 성능이 요구되는 경우 Rich Docuemnt 구조로 설계하는 것이 유리 (Data Model Design 참고 / Embedded Document도 고려)
- 메모리 부족으로 인한 성능 저하로 메모리 증설도 고려
- Shard Key 의 중요성,(1~5) Balancer는 유휴 시간대에 작업 추천(3), 적절한 Shard 수(4), 메모리도 체크(5)
참고
- https://nesoy.github.io/articles/2018-05/Database-Shard
- https://m.blog.naver.com/PostView.nhn?blogId=ijoos&logNo=221330154774&proxyReferer=https:%2F%2Fwww.google.com%2F
- https://woowabros.github.io/experience/2020/07/06/db-sharding.html
- https://velog.io/@matisse/Database-sharding%EC%97%90-%EB%8C%80%ED%95%B4
- http://clearpal7.blogspot.com/2017/05/mongodb-config-servers.html
- https://m.blog.naver.com/PostView.nhn?blogId=icysword&logNo=220450944786&proxyReferer=https:%2F%2Fwww.google.com%2F
- https://sarc.io/index.php/nosql/1703-mongodb-chunk-1
- https://docs.mongodb.com/manual/core/sharding-balancer-administration/#sharding-internals-balancing
- MongoDB Master가 해설하는 New NoSQL & mongoDB - 서적 참고
반응형
'MongoDB > MongoDB-Study_완료' 카테고리의 다른 글
| [MongoDB] [Study-Break] Cursor 간략한 정리 (0) | 2021.03.27 |
|---|---|
| [MongoDB][Study-4] MongoDB 기본 명령어 익히기 (0) | 2021.03.27 |
| [MongoDB] [Study-2-2] P-S-A 구성 (0) | 2021.03.27 |
| [MongoDB] [Study-2-1] Wired Tiger (WT엔진) (0) | 2021.03.27 |
| [MongoDB] [Study-1] MongoDB 이란? (0) | 2021.03.27 |














.png)

.png)
